
着篇我们来分享 innoDB buffer pool
- buffer pool 介绍
- 普通索引和唯一索引怎么选 (这其实说的是change buffer 利用...)
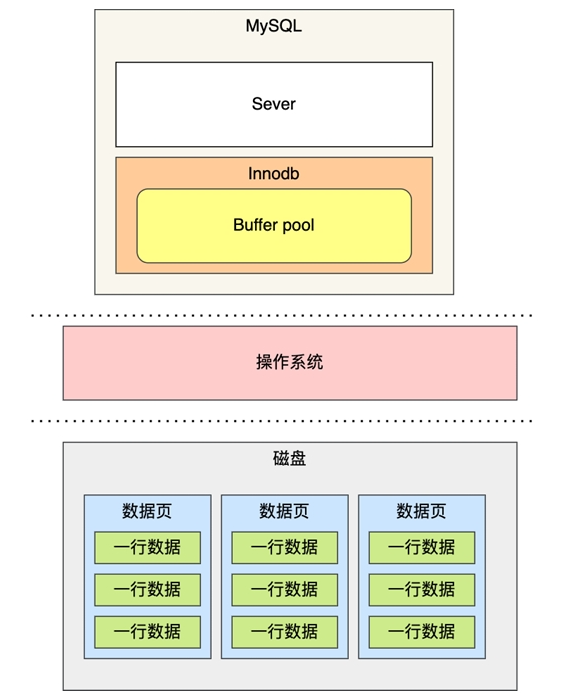
InnoDB buffer pool 干什么的?
-
一句话概括,将磁盘数据和内存连结起来,批量管理I/O 提升读写性能。
buffer pool 大概是这样的
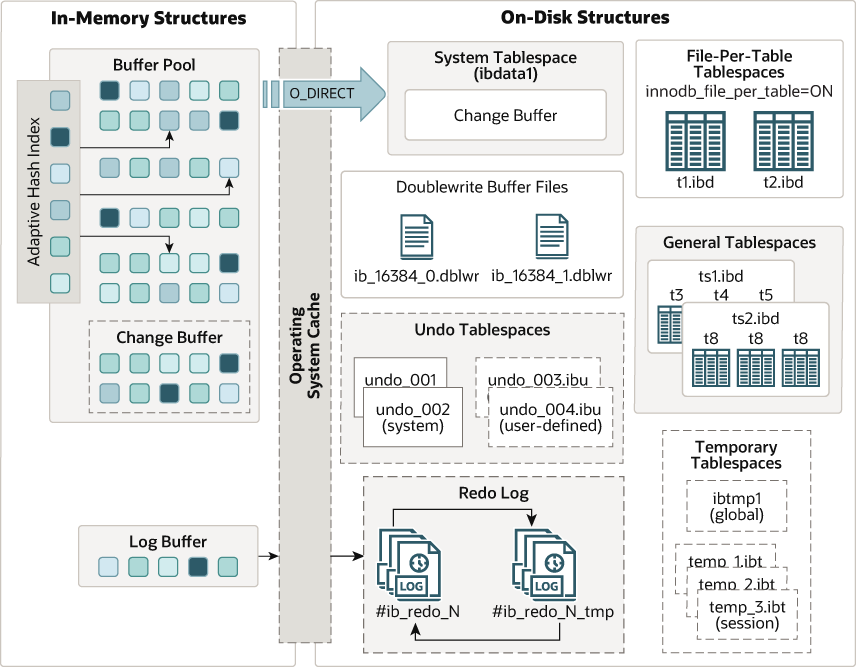
简化一下,偷个小林哥的图
buffer pool 里有什么?
还是偷个小林哥的图:
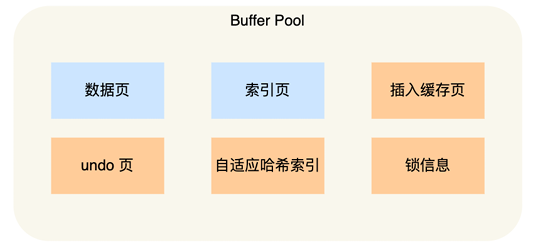
- buffer pool 里面缓存有索引页、数据页、插入缓存页、undo页、自适应哈希索引、锁信息、change buffer页等。
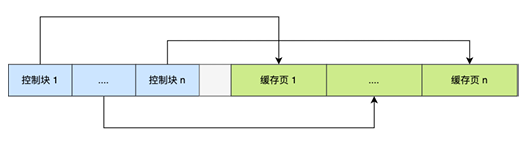
Buffer pool 中的页结构
为了更好管理buffer pool 中的众多缓存页, buffer pool 给每个页都加入了索引: 在buffer pool 的最前端部分为每个缓存页创建了控制块,控制块里存着缓存页的归属页表空间,页号,缓存页地址,链表节点。
偷个小林哥的图:
查询语句是buffer pool 中式如何缓冲加速的?
- innoDB 回提前预读数据,如果在同一页中的数据之前被访问过,这次查询的数据会直接通过B+树二分查找找到对应索引页,通过二分查找页目录槽,遍历指向的数据记录组即可找到对应数据。
- 所在数据页未被缓存,会向磁盘读取该页,在查页目录遍历数据组返回数据。
buffer pool 如何管理数据页?
数据页有三种状态:空表页(未被使用的页)、clean 页(已缓存,为修改数据页)、dirty 页(被修改过的页、写入数据的空白页)。
buffer pool 在内存中是一片连续的内存空间,想要管理这些页,innodb引入的三个链表,用于管理上面的三种状态的页和加速访问这些页。
Free list(空页链表)
为了能更快获取空白页,InnoDB 使用Free list 管理预先申请来的空白页。
这里偷个小林哥的图继续说.
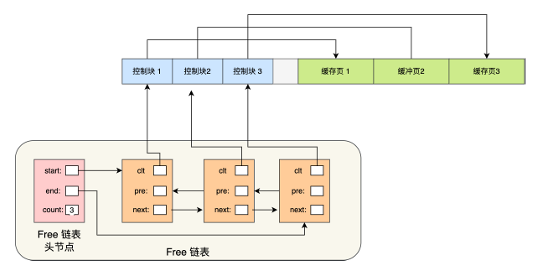
空白页链表结构大概是这样的:
- 空白页链表是一个双链表,头节点存空白页链表第一个节点地址、最后一个节点地址、链表节点个数
- 空表页链表节点和空白页链表节点之间通前后继指针链接,节点中有一个空白页控制块指针指向对应空白页控制块地址
如何使用空白页?
当需要从磁盘中加载数据页到buffer pool 时,先从空白页链表取一个空白页,填充从磁盘读取上来的数据,把该页从空白页表中移除,将该页加入到LRU链表中。
Dirty list (脏页链表)
结构同上Free list 空白页链表:
偷个小林哥的图
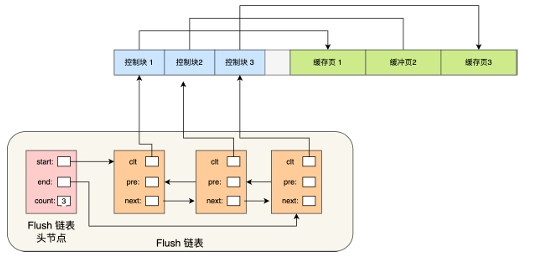
脏页什么时候落盘?
为了提高性能,脏页不会马上落盘,而是将buffer pool 中被修改的页标记为脏页,在dirty list (脏链表上计入该页控制块对应节点),之后会由后台flush 刷盘线程统一定时定量写入磁盘。
InnoDB 中的LRU 页面淘汰(LRU链表)
内存资源是有限的,如何能让热点数据较长时间的驻留在内存中,让访问时不用经常进行磁盘IO就是众多缓冲型内存池需要考虑的问题,InnoDB 采用的时改进的LRU 算法来保障热点页尽可能的驻留在内存中。
这里偷个小林哥的图
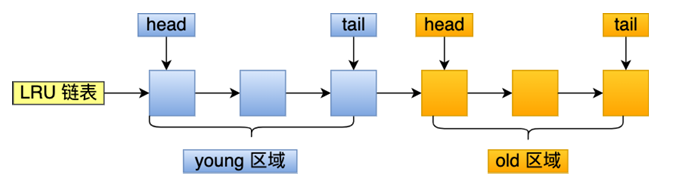
上图就是innoDB 改进LRU的页链表示意图,可以看到LRU链表被分为了两段,young区,old区, LRU链表结构和运行规则如下:
- LRU 链表young 区默认占链表 63%,old 区 37%, 最大可设置占比 50:50
- 新缓存页从old 区 被访问,或从磁盘中被加载访问,该页会更新访问时间戳,并将该数据页插入到old区头部,old区末端如果由页面被淘汰,如果该页为脏页,则会进入到flush 链表,等待后台落盘线程统一落盘。
- 因被访问使得被视为较活跃得数据页在old区头部会有old区驻留时间阈值(用来比较: 当前次访问时间戳- 最后一次访问时间戳 >= ? 驻留时间阈值),下次访问时和上次时间戳做差比较驻留阈值,若大于,则人文该页为热点页移动到young区头部,否则保持原来位置。这个阈值是 innodb_old_blocks_time 控制的,默认是 1000 ms。
问什么会设计 这个驻留阈值?
因为这么设计,会导致buffer pool 缓存污染,若干次只访问一次得缓存页会频繁插入到young 区头部,着会使得young区链表会不停的被移动。影响热点访问小效率。
比如执行一个索引失效,返回结果只有几个SQL,就会复现次现象,因为索引失效导致引擎必须扫描全表,导致不断由新数据载入移动到链表头部...
InnoDB change buffer
chanage buffer 长什么样?
看图:
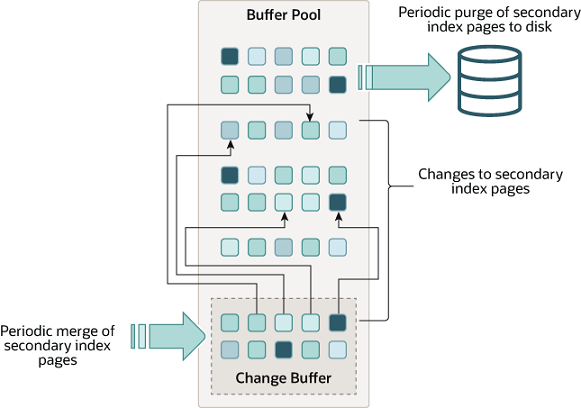
change buffer 干什么的?
管理脏页的buffer, 默认占buffer pool 25%, 最大50%。内存类buffer 都由一个统一的用法:加速数据访问、较少I/O次数+统一I/O管理。change buffer 页也不免落入次套路,对于不在buffer pool 中的数据进行DML(insert/delete/update)时可先在缓冲页中先DML 后面标记为脏页,后面由落盘线程统一落盘。
如何工作?
change buffer : 只需要注意 merge 机制即可。下面将构造场景,解释如何利用merge 机制由化多写业务。
- 对于插入,如果change buffer 中由对应数据页且由位置可插入,数据插入完成后,打上dirty 标记,change buffer 会加入该页索引,如果没有地方可插入,可从free list 中申请一页,写入数据,加入到change buffer 中。
- 对于delete,update 也是如此
- merge 机制,在修改一条不在缓存中的数据时,会直接将该变更操作直接记录到change buffer 中,同时记录下unolog 和 redolog. 在这条数据对应的数据页被读取请求载入到buffer 时会将change buffer 中的修改合并到载入的数据页中,由后台线程统一落盘。
- merge 触发时机:数据页被载入buffer、后台线程定期触发merge、mysql 正常关闭
- 有唯一约束(主键、唯一约束键)使用change buffer 回事内存缓存减少磁盘I/O 优化特性失效,因为唯一约束在update/insert 时会查询该键是否有记录,有才会操作,这回会立即请求磁盘载入数据,merge被触发。所以在merge 触发前对change buffer 中的修改命中越多,该项优化带来的收益也就越大。
利用change buffer merge机制优化业务
有一个日志场景,结构导如下:
|timestamp int(primary key)|log level char|message varchar|
字段 timestamp 时间戳精确到毫秒,一毫秒产生一条数据,一秒需要写入1000条数据。该表上先之后发现,MySQL I/O 次数突然陡增,导致后面其他表的查询和DML 遭到不同程度的延迟。
iostat 后发现
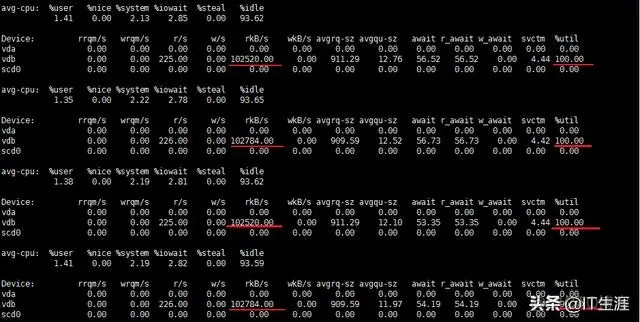
磁盘读过高。
use performance_schema;
select * from file_summary_by_instance order by SUM_TIMER_WAIT desc limit 5\G;
后发现是操作 日志.idb 最耗时间。
逐去排查操作日志的语句。发现仅有一条
insert into __log value(...),(...);
语句应该没有问题,所以就试着注释这条语句,iostat 发现磁盘I/O 骤降。逐去排查表定义,去官网翻手册,最后发现是因为 timestamp 是主键做DML操作时需要读缓存检查主键是否存在这回导致频繁数据读取可能引起频繁读盘,去看了change buffer merge 特性,因为业务上已经可以保证时间戳使唯一的了,逐把 timestamp 改为 普通列,在orm 写数据前加入时间戳不为空判断。iostat I/O 频繁现象消失。

