
这是MySQL 学习日记的索引篇 ...
索引是什么?
索引使一种加快数据查询的数据结构。
索引分类
按数据结构分类:
- 树形索引 O(log2n)
- 哈希表索引O(1)
- 全文索引
按数据存储位置分类:
- 聚簇索引
- 非聚簇索引
为什么索引能加快查询?
因为索引是有序的,可以进行二分查找这是数据结构的天然优势。在InnoDB 中,同时支持两种索引:聚簇索引,非聚簇索引。二者都基于B+ 树实现,B+ 树数据结构稳定,节点中可以存储一定量数据,节点之间用双向指针指针链接,查询访问更块。因为B+ 树数据结构足够稳定,不容易裂项,调整树高,所以在海量数据下,一次查询最多也只会进行3-4次I/O,查询效率极佳。
MySQL 支持那些索引?
B+ 树、哈希、R树、全文索引。
为什么选用B+ 树作为索引数据结构?
一下做逐项对比,便可知为何使用B+树做索引:
- 对比二分查询找树:二分查找树会退化为链表,数据结构抗异常数据特性差,或者说算法不稳定。
- 对比于B树(自平衡树):自平衡树由于数据的插入删除频繁会导致数据结构频繁变动,数据结构不稳定,维护代价大,得不偿失。
- 对比于哈希表:哈希表查询效率绝块,但数据无序,无法直接支持范围查找,和排序。
- 对比于传统B+ 树,同级节点之间不能相互访问,仍可优化。但仍是可考虑的数据结构。
综上比较,InnoDB 选用了B+树做为数据组织的结构原因,并在同层节点之间加入前后继指针,使数据查找更为方便。
建立索引优缺点?
优点:
- 改进的B+ 树查询效率极佳,50亿的数据最多只需要3-4次I/O 即可完成一次查询
- 同层节点之间可正反向遍历,支持范围查询
- 数据结构特性,数据存储天然有序,排序无序做额外工作。
缺点:
- 索引的维护是需要内存资源和CPU资源维护的,数据量很少时,建立索引不见得是一个极佳的实践。
- 随机无序数据插入需要做裂项分页,资源花销不小。
B+树索引插入性能
有序正序或反序:维护代价极小,不需要频繁裂项分页。典型例子:自增UID。
随机插入:需要频繁裂项分页。
偷一张小林哥的图,InnoDB B+树:
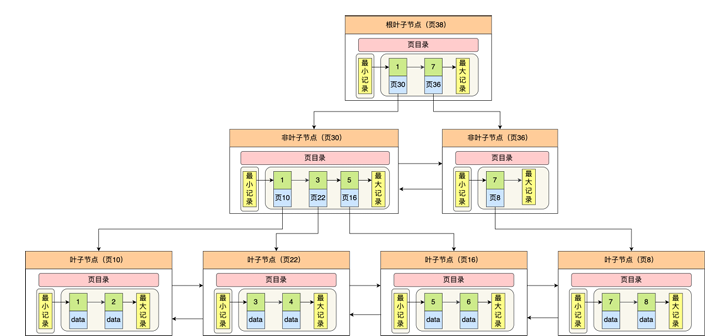
索引组织表和堆表区别?
这只是一个数据组织的概念,勿念。其实优点抽象的
区别就在于:叶子节点是否存储数据
-
索引组织表:InnoDB 使用的数据组织方式,非叶子节点存索引,存少量数据,叶子节点存大于等于非叶子节点的数据(全量数据)
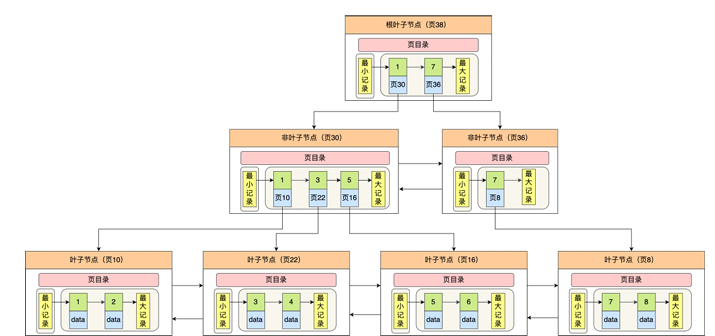
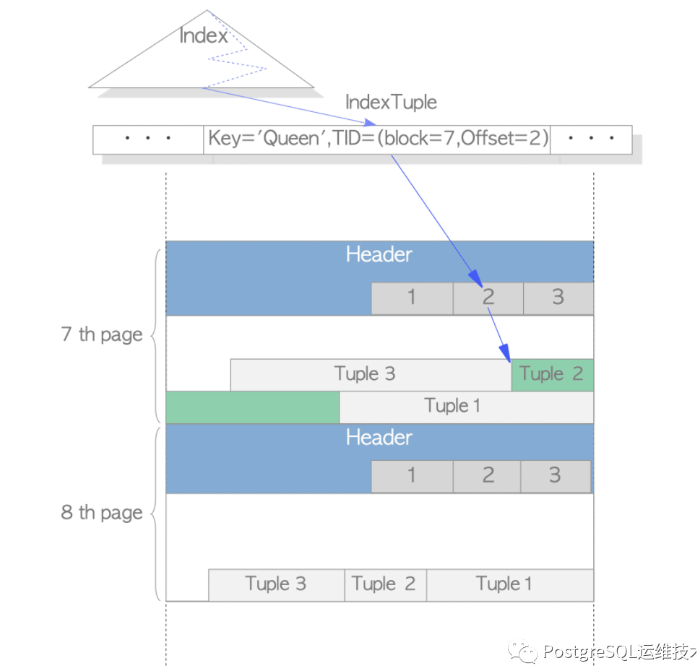
-
堆表:MyISAM 使用的数据组织方式,树节点只存一个key,用于比较查找,其他数据统统存数据文件中,通过节点的数据指针建立行-节点索引关系。
联合索引结构是什么样子的?
InnoDB 中联合索引长这样:
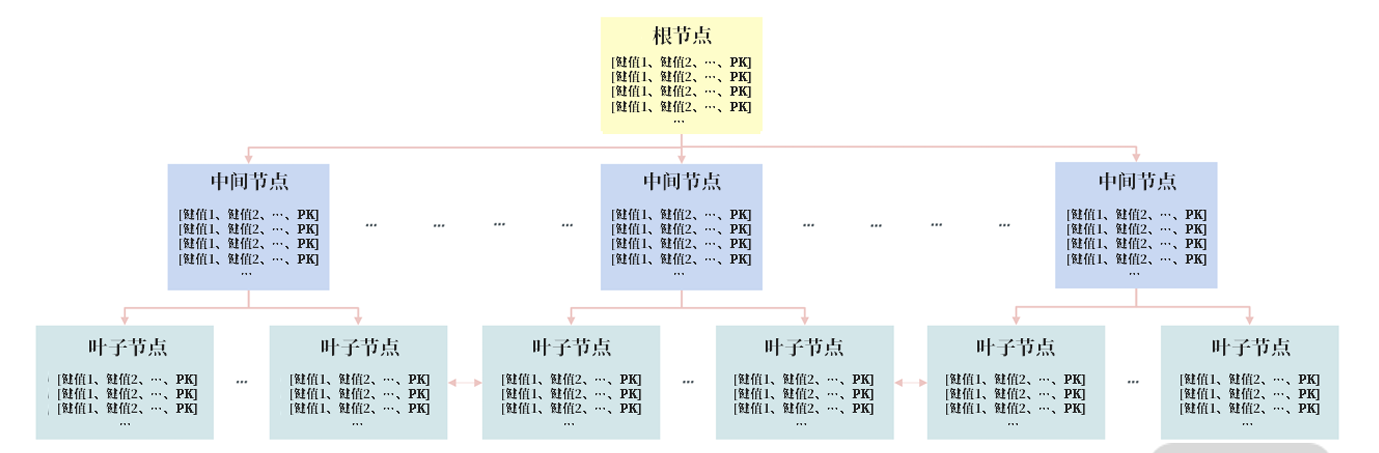
如何利用联合索引提升查询性能?
遵从一下几点即可:
- 注意索引失效场景
- 联合索引键顺序按业务范文热度排序
- 遵从最左匹配原则
- 查询联合索引时,就算不用第一个索引键,也要把带上
- 必要时可创建直方图,让索引知道数据分布。避免优化器成本评估错误,下面时直方图创建:
ANALYZE TABLE data_table_name UPDATE HISTOGRAM ON sheet_name;
联合索引如何加速查询的
- 索引在覆盖充分情况下,可以避免回表
- 在范围查询时,索引天然有序,可不用排序即可做范围遍历
- 索引数据结构天然支持排序,索引在有排序需求时,可以直接获取索引存储的数据
原理是什么?
- 减少回表
- 不用再做排序
Tip: 回表,辅助索引会节点中会存储,数据行的主键,在索引树中的数据无法直接满足查询需求时,就需要拿着对应的主键会主键索引查剩余记录。这个过程就是回表
索引失效场景
索引失效场景多发生在where
- 隐式转换: 注意字符类型和整数类型之间
- 模糊查询: %valu, %val%
- 注意范围查询:开区间查询会失效,但闭区间可以
- OR 查询
- 最左匹配
- 优化器成本评估失效
- 索引键参与预算而不作为左值被赋值
- 索引键对函数结果进行匹配
- 前缀索引,不知道全文,不支持。
- 反向集合查询:NOT IN、NOT NULL、!= 等
MySQL 优化器
这里之说成本优化部分,优化器会本根据成本,成本公式见下:
cost = SERVER COST + ENGINE COST
= MEMORY COST + CPU COST
查询各成本数语句见下(查询成本表):
select * from mysql.server_cost;
一句SQL 执行的成本
explain select * from table_name \G
如果存在多条索引,优化器会枚举各方案的查询成本,选择最小成本的计划执行。
explain
type 查询类型:
- all 全表扫描
- range: 区间查询
- index: 辅助索引查询
- const: 使用主键/唯一 键查询
- eq_ref: 表连接查询
possible_key: 考虑使用的索引
key: 本次查询中使用的suoyin
key_len: 使用索引占字节长度 --- 看联合索引是否全部使用时有用,比如 key1 < val and key2 = xxx
extra 额外信息:
- using filesort: 索引字段之外的方式尽心查询
- using index: ...
- using index condition: 索引下推
- using temporary : 使用了临时表
优化器如何选择索引?
这里主要分享优化器一些事出有因的选择。
1.优化器认为数据区分度不大,索引扫描和全表扫描访问量一样时。比如性别
2.辅助索引没有全覆盖,检索完辅助索引中的数据,需要用输出数据创建临时表批量回表
如何正确使用索引
那些场合适合建立索引?
- 字段最好有唯一性限制
- where/group by 常用字段
那些场合不适合建立索引?
- 数据量少
- 字段频繁删改的字段
- 数据量大,存在大量重复值,且无数据倾斜的字段
- where\order by\group by 用不到的字段
使用技巧
可以是使用
show status like '%Handler_read%';查看当前会话的索引使用情况。
show global status like 'Handler_read%'; 查看全局索引使用情况
查看索引使用情况,尝试删除无用索引前,可尝试使用(MySQL 8.0)
alter table table_name index index_name invisiable;
将索引设置为不可见,在使用explain 观察分析,确认无用之后在删除。

