
这篇主要分享下面几个主题:
- char 和varchar 区别
- InnoDB 中数据页的之间的关系是如何组织的
char 和 varchar 区别
- 空间分配区别: char 会立即分配定义的长度,varchar 不会
- 存储最长上限:char 0-255,不足声明长度会在尾部填充空格,varchar 原封不动
- 存储格式: varchar 存储小于255个字符时,会在串的头部有1byte 记录串长度,超过255变为2byte. 字符串最长65533
- 是否截断存储串末尾空行:char 会,varchar 不会
InnoDB 中数据页的之间的关系是如何组织的
OS: 其实这里主要讲的B+树
InnoDB 是以 B+树的形式区组织数据存储的。数据足够大的时候B+树上的节点会裂项,数据会下沉到叶子节点,在大点,页子节点的数据会存储到磁盘中。
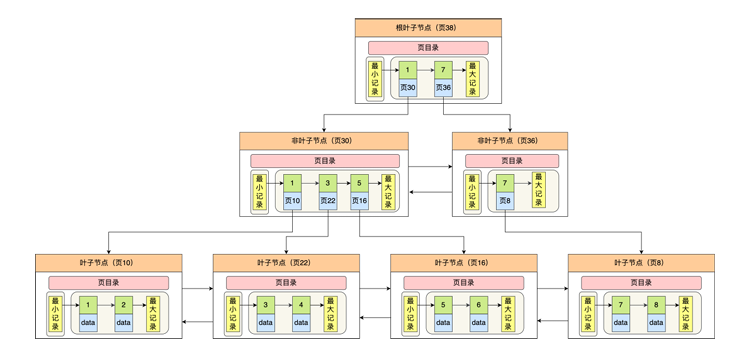
从上图可以看书数据页在B+树叶子节点值上的节点以索引形式存在,叶子节点存储着数据。查找时通过二分比较可以在较短的时间内找到数据对应的数据页。之后访问数据页遍历,即可找到对应数据。
相邻的数据页之间是如何组织关系的?
先看图后说话

放大:
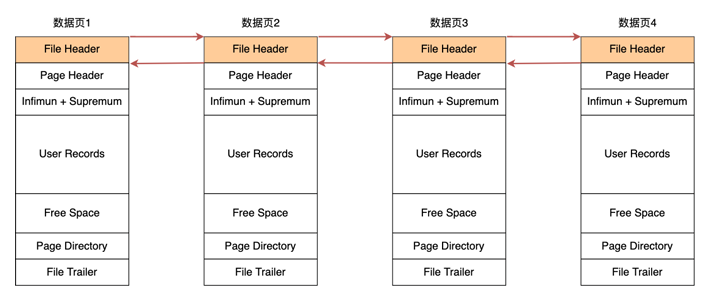
相邻之间的数据页通过页头头尾指针链接,页和页之间串联起来就会形成双向链表。
数据页的存储格式
先看图后说话:
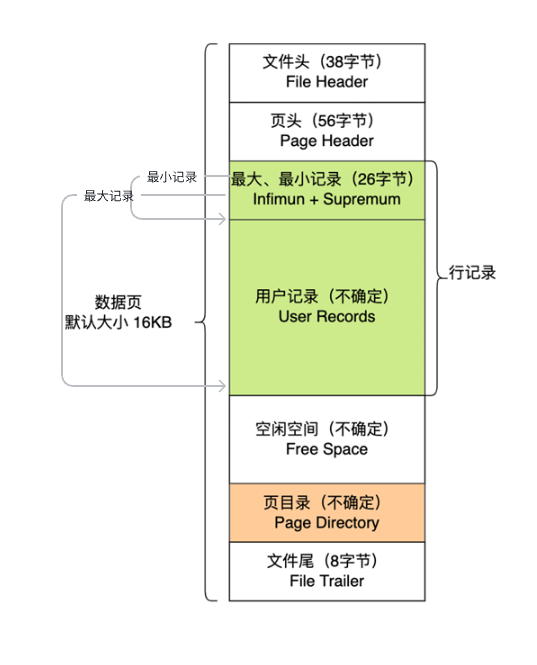
数据页分为七部分存储:
文件头
- 存储这个页的信息
页头
- 存储这个页的状态信息,是否例如这个页 clean or dirty
- Tip: clean 可能这个页挂在LRU 链表上,未被修改,dirty 这个页数据被修改过,需要merge or flush to disk.
最大最小记录
- 用户数据段数据行的首位指针,指向用户数据段的首行数据和最后一行数据
用户数据
- 存储下来的记录行
空闲空间
- 空闲段每页16k
页目录
- 记录行数据索引,加速访问
- Tip: 数据行和数据行直接按是以单链表形式链接
文件尾
- 整个页的校验和
这里我们关心的是一行数据查找,到数据页后如何找到对应数据行,这其中,最重要的就是要查页索引了
页索引 - 如何找到一行数据
看图说话,数据页中的页索引是这样的:
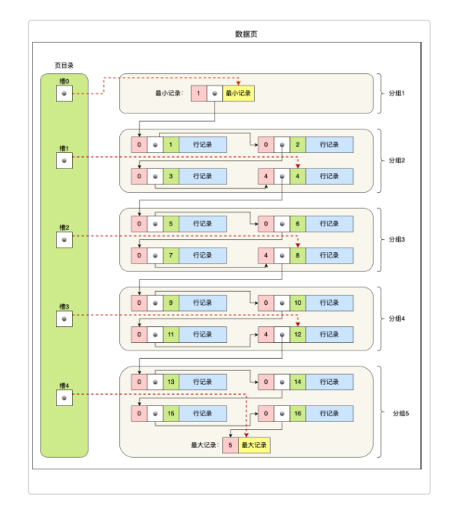
页目录分组规则
可以看到,页目录是由分组的,分组规则大概是这样:
- 目录页第一个槽,固定存储用户记录行的第一条数据地址
- 目录页最后一个槽,固定存储用户记录的最后一条数据地址
- 中间的槽指向分组数据组的最后一条数据记录地址
- 每个分组大小有4-8条数据。
- 第一个槽,指向的数据组,只能有第一条数据。
数据页中行记录存储规则
- 按主键顺序排序存储
页目录创建
- 排除有删除标记的页,按照上面规则分组
- 将分组后每组记录数据记录到每组最后一条数据的头信息的 n_owned 字段中
- 将记录页中每个槽指向每个分组的最后一条记录地址。
聚簇索引和辅助索引
- 一张表只能有一个聚簇索引(主键索引)
- 辅助索引存放着主键和索引设定的键值
- innodb 非覆盖索引下通过辅助索引查找到数据后需要根据主键回主键索引查剩下数据。这个过程就是回表
- 能通过辅助索引查到所有数据不用回表的擦寻就叫索引覆盖查询。这个就叫索引覆盖

