
1.跳表是什么?
标准跳表是一个元素有序的遵循相邻层节点数比(相邻上下层)是2:1的链表。由美国计算机科学家发明于 1989 年
redis 中的跳表是基于标准跳表改进而来,采用幂次定律 (power law,越大的数出现的概率越小) 改进了标准跳表因为需要严格保证相邻上下两层严格2:1 比例使得在增删节点是导致的跳表的reblance现象。且跳表节点增加了前驱指针方便实现ZREVRANG 功能.
效率方面,跳跃表的效率和 AVL 相媲美,查找/添加/插入/删除操作都能够在 O(LogN)的复杂度内完成。
2.跳表的结构?
偷个大佬的图
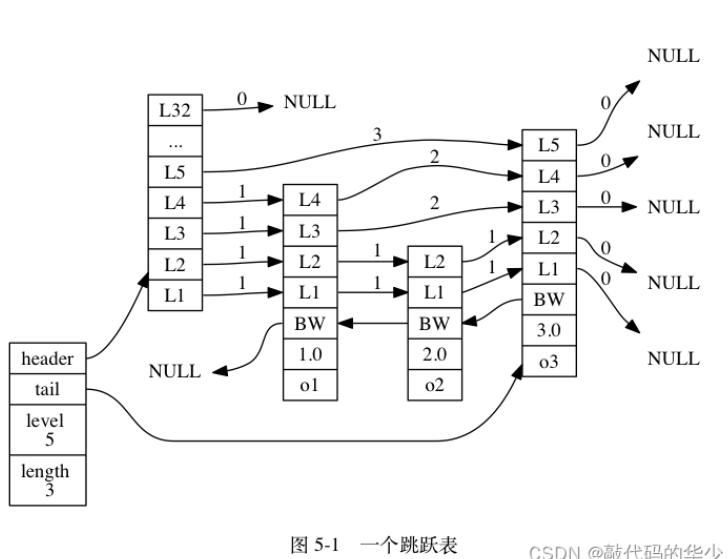
具体点是这样:

跳表由一个带由存有跳表元信息(首节点指针、末尾节点指针、最高层数、元素个数(长度))的表头和跳表节点组成,其中节点的层高是随机的成幂定律分布(相邻层的节点比例不是标准跳表的2:1).
3.Redis跳表实现?
看上面的图
再看代码
// file: server.h/zskiplistNode
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
//后退指针
struct zskiplistNode *backward;
//分值:用于排序,跳跃表中的所有节点都按分值大小进行排序
double score;
//成员对象:即真正要往链表中存放的对象
// or: sds ele;
robj *obj;
//层:每个节点都包含很多层,每一层指向的都是同一个对象
struct zskiplistLevel {
//前进指针
struct zskiplistNode *forward;
//跨度
unsigned int span;
} level[];
} zskiplistNode;
typedefstruct zskiplist {
//表头节点和表尾节点
struct zskiplistNode *header, *tail;
//表中节点的数量
unsignedlong length;
//表中层数最大的节点的层数
int level;
} zskiplist;节点的成员对象 (obj 属性) 是一个指针,它指向一个字符串对象,而字符串对象则保存着一个 SDS 值。
层的跨度(level[i].span 属性)用于记录两个节点之间的距离
初看上去, 很容易以为跨度和遍历操作有关, 但实际上并不是这样 —— 遍历操作只使用前进指针就可以完成了, 跨度实际上是用来计算排位(rank)的: 在查找某个节点的过程中, 将沿途访问过的所有层的跨度累计起来, 得到的结果就是目标节点在跳跃表中的排位。
4.Redis跳表单个节点有几层?
跳跃表节点的 level 数组可以包含多个元素,每个元素都包含一个指向其他节点的指针,通过这些层来加快访问其他节点的速度,一般来说,层的数量越多,访问其他节点的速度就越快。
每次创建一个新跳跃表节点的时候,程序根据幂次定律 (power law,越大的数出现的概率越小) 随机生成一个介于 1 和 32 之间的值作为 层高。
5.0 64/ 7.0 32
5.Redis跳表的性能优化了多少?
跳表的查询思想认识二分法,二分的复杂度是O(log2N),传统平衡查找树因为需要严格保持树的左右分支平很所以查找效率总是O(log2N) 是稳定的,但是跳表最坏的情况下会出现O(N)的情况,单跳表会出现查找树为了维持平衡做reblance 这个步骤,综合生产(存有大量数据时)情况来看大致都会从O(N) 优化到O(log2N).
INTERVIEW
1. 跳表是什么,和普通的链表有什么区别?
从结构上来讲,二者都是链表,但是跳表是一个随机化的数据结构.
从时间复杂度来讲,他的查找效率的在生产环境中大部分情况下都是O(log2N),因为跳表支持二分查找,且在有序情况下可以在O(log2N) 的复杂度获取指定节点的Rank 值,这对排名系统来说是一个很重要的特性,但在链表中却需要O(N)
2. 聊聊跳表的查找过程。
二分厂找的过程,从最高节点开始访问,目标值和当前节点比较,大于 往右,小于往左,继续上面的步骤,若目标值在高速节点中,那么直接返回,否则继续上面的步骤,直到下降到最低层的节点,若直接命中则直接返回,否则往左或者往右遍历有限步即可返回有或无.
3. 跳表查询节点总数的平均时间复杂度是多少?
跳表结构提定义中/跳表表头中有记录元素个数的成员,查询直接返回这个值,所以时间复杂度O(1)
4. 跳表中一个节点的层高是怎么决定的?
标准跳表是由数据量决定的,相邻两层之间的节点数下比上 的示例大致是 2:1 , 正式由于标准跳表遵循这个比例,所以增删改,都会导致类似AVL树那样需要做reblance的情况
redis 跳表为了避免频繁的reblance 请款导致性能稳,引入了幂次定律函数通过这个函数去决定这个节点是底部基本节点还是层高是某值的高速节点,5.0 最大层数是64 层,7.0 是32,层数越高出现的概率越低。
5. 跳表插入一条数据的平均时间复杂度是多少?
O(log2), 新节点会通过幂次函数决定高度,不论这个节点最终是高速节点还是基本节点,数据插入都需要通过跳表进行二分查找找到对应元素位置修改指针指向完成插入,所以时间最要花在查找位置上所以大部分情况下是O(log2N)
6. 跳表插入数据会影响其它节点层高吗?
不会发,新节点在插入前已经通过幂次算法生成好了层高,之后就不会再次修改。或者说Redis 里的跳表没有reblance 机制,且随机幂次函数的引入也是为了规避reblance这个 性能步稳定点.

