
1.ZSET是什么?
根据一个有权重的KV(val 就是存储权重)存储合集
2.ZSET适用场景?
需要排序的场景,比如游戏里的排行榜,人气榜什么的...
3.常用操作
偷图
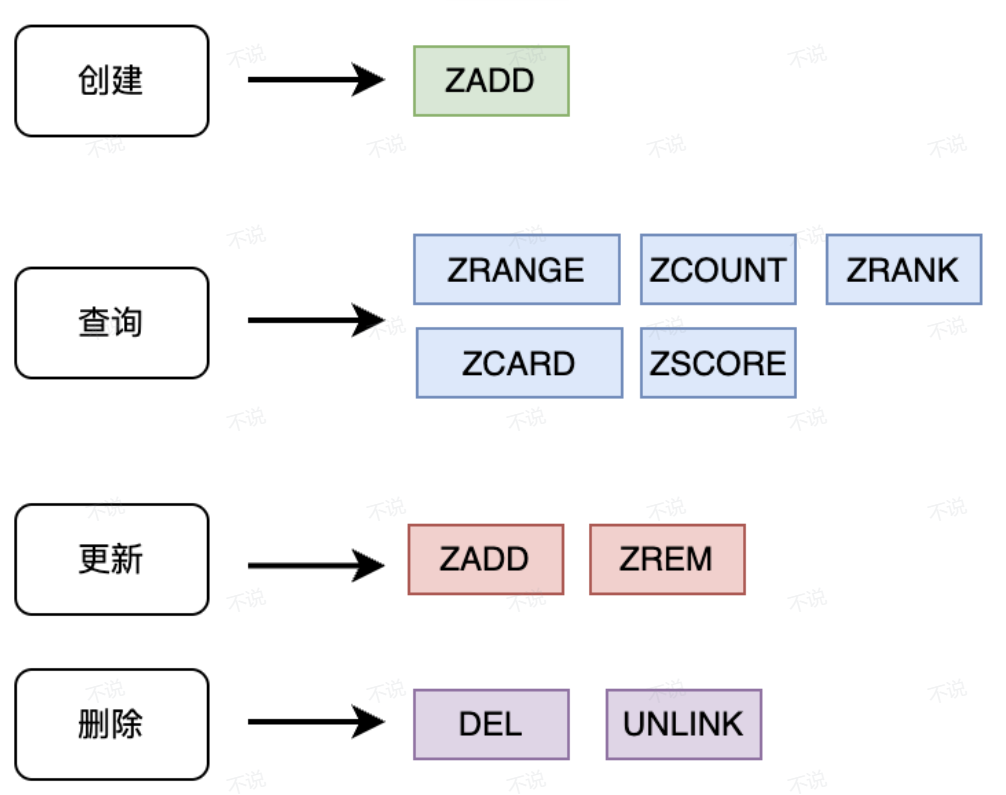
ZADD key[zset_name] weight1 value1 weight2 value2 ... : weight 键值对排序权重,权重越小越靠前(排序规则:从小到大).
扩展参数:
XX: 更新已存在的元素,不存在的不新增(新建)
NX: 不更新已存在成员,只添加新成员
LT(little than): ZADD key[zset_name] LT weight1 value1 weight2 value2... 按条件更新指定指定键值对,若当前输入的新权重于原理键值对的权重值则更新成功,否则不更新
GT(greater than): ZADD key[zset_name] GT weight1 value1 weight2 value2... 按条件更新指定指定键值对,若当前输入的新权重大于原键值对的权重值则更新成功,否则不更新
注意:GT、LT 和 NX 选项是互斥的。
ZRANGE startIdx endIdx [WITHSCORES] : [WITHSCORES 选填参数,不写输出只有key,没有权重] 从小到大遍历
ZREVRANGE startIdx endIdx [WITHSCORES]:和上面相反,从大到小遍历
ZCARD: 和SCARD 一样都是查看成元数
ZCOUNT key min max 统计权重在[min,max] 区间内的成员个数.
ZRANK key[zset_name] val 查看成员在zset 的中的排名,排名时从0开始的[0,1,2 ....]
ZSCORE key[zset_name] val 查看成员的权重值
4.ZSET底层实现
偷个图
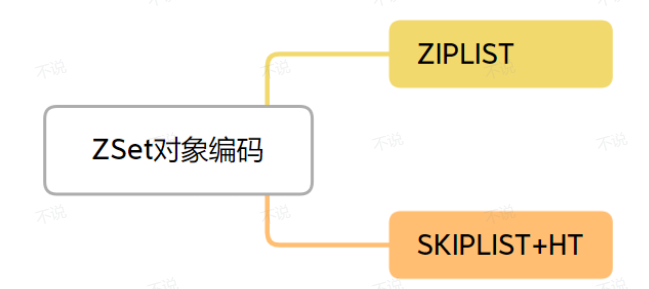
ZSET 有两种编码格式: ZIPLIST、SKIPLIST + HASHTABLE
ZIPLIST 在 ZSET中的存储布局
偷个图

使用条件(两个条件必须满足):
所有字符串元素长度都小于64字长
键值对个数少于128个
不满足则转化为跳表
SKIPLIST
偷个图
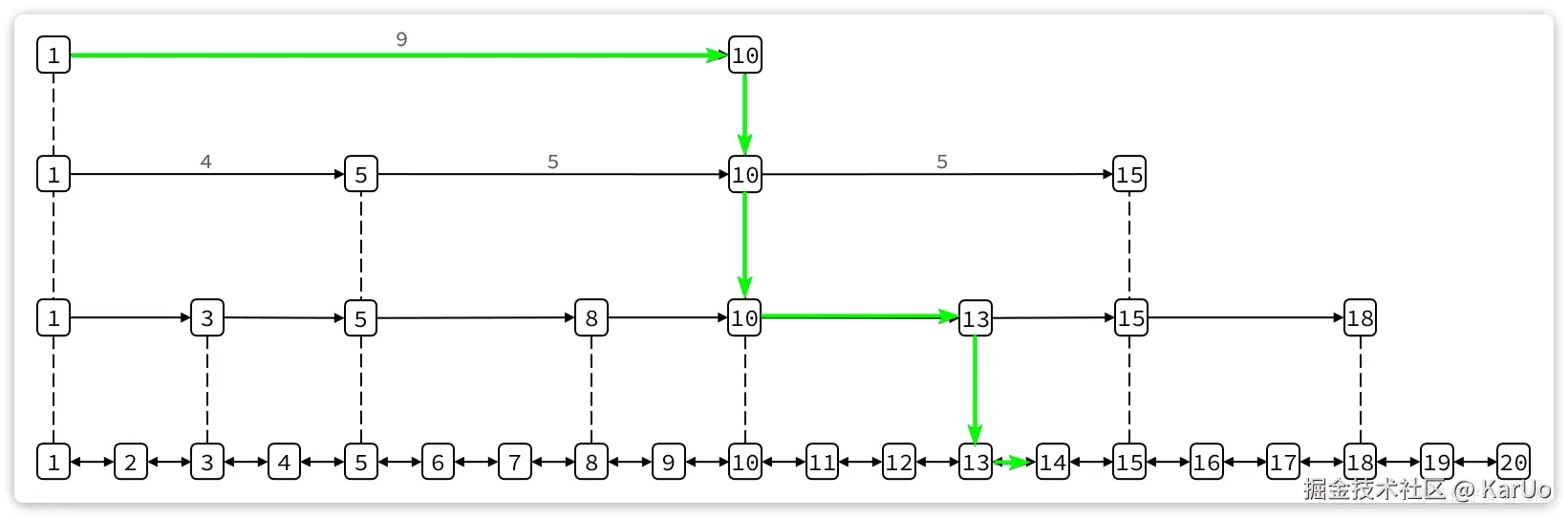
概念:
跳跃表(SkipList)是一种可以替代平衡树的数据结构。跳跃表让已排序的数据分布在多层次的链表结构中,默认是将Key值升序排列的,以 0-1 的随机值决定一个数据是否能够攀升到高层次的链表中。它通过容许一定的数据冗余,达到 “以空间换时间” 的目的。
跳跃表的效率和AVL相媲美,查找/添加/插入/删除操作都能够在O(LogN)的复杂度内完成。
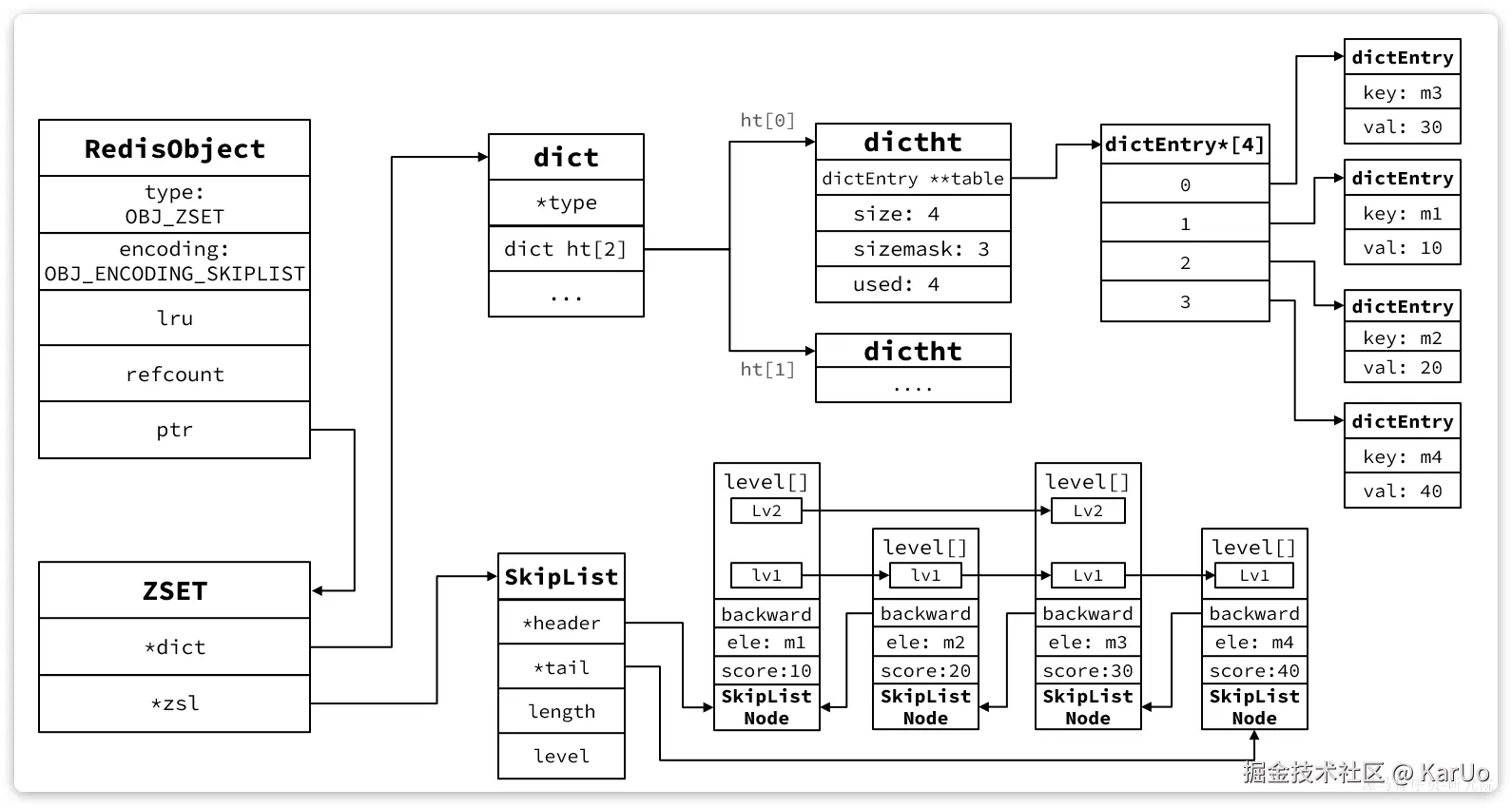
SKIPLIST + HASHTABLE
偷个图,看到佬的图比我说的强
INTERVIEW
1. ZSet如何添加元素,如果移除元素?
ZADD
ZREM
2. ZSet如何从大到小查找范围?
ZREVRANG
3. ZSet底层有几种编码方式?
ZIPLIST
使用条件:
a.所有字符串元素长度都小于64字长
b.键值对个数少于128个
SKIPLSIT + HASHTABLE(ZIPLIST 使用条件有任一不满足就是用该编码)
4. ZSet查询节点总数的平均时间复杂度是多少?
看源码
// 这段代码是Redis中用于获取有序集合(sorted set)长度的函数。下面是这段代码的摘抄和注释:
// 定义一个函数,用于获取有序集合的长度
unsigned int zsetLength(robj *zobj) {
int length = -1; // 初始化长度为-1,表示未确定
// 如果有序集合使用的是ZIPLIST编码
if (zobj->encoding == REDIS_ENCODING_ZIPLIST) {
length = zzlLength(zobj->ptr); // 调用zzlLength函数获取ZIPLIST的长度
}
// 如果有序集合使用的是SKIPLIST编码
else if (zobj->encoding == REDIS_ENCODING_SKIPLIST) {
length = ((zset*)zobj->ptr)->zsl->length; // 直接从zset结构体中获取长度
}
// 如果编码类型既不是ZIPLIST也不是SKIPLIST,则触发panic
else {
redisPanic("Unknown sorted set encoding"); // 打印错误信息并触发panic
}
return length; // 返回有序集合的长度
}若是使用ZIPLIST编码则直接从zllen 返回,O(1)
使用SKIPLIST + HASHTABLE 则从zset 定义的结构体中返回 length 成员值,O(1)
5. ZSet为什么将跳表和HashTable要配合使用?
这样做其实是以空间换时间的做法,因为无论是链表还是数组类型的编码结构查找某元素在能使用二分查找下的效率最快不过是O(log2N)
使用HASHTABLE 编码结构时为了单KEY查询优化到O(1);
但是因为ZSET设计时就确定是一个有序的集合,那么范围查询时不可少的一个需求。字典结构的数据关系-存储结构也决定了数据在字典这种结构中是无序的(且为了保持足够简单和职责单一性,所以没有在HASHTABLE 编码上去实现范围查新),所以引入SKIPLIST
SKIPLIST 有跳跃节点且是双向链表,遍历实现简单且效率高
6. ZSet为什么用跳表而不是B+树?
结合MYSQL 和 REDIS 来回答:对比两数据库数据存储设备和需求场景来说,MYSQL 设计的时候就可以接受一定数据查询延迟,且使用了磁盘做大量数据的持久化,所以用B+树取做数据关系结构是合适的,从B+树的结构上来说,为了较少磁盘I/O 次数所以B+树被希望尽可能的矮胖,这样就能减少磁盘读此书,那么,B+树的索引节点就不能存储大量数据只能用叶子节点存储数据(因为存海量数据存索引中,那么索引查项就会因遍历变慢),利用磁盘I/O调度器预加载相邻区域数据的特点可以一次性读取很大一块数据上来这刚好也符合B+树叶子节点存数据的特性,所以MYSQL 用B+树,而不是用跳表,REDIS 刚好和MYSQL 相反,要求高效极速,低内存,所以数据不能存磁盘中,且跳表实现简单也不会出现B+树大索引裂项的从而导致树分支需要rebalance的情况,这就是为甚么redis 使用跳表的原因.
7. ZSet为什么用跳表而不是用红黑树?
redis 作者回答:调表实现简单
调表的性能不必其他AVL平衡树,内存使用、缓存局部性也都不比平衡查找树差

