
这节我们扯底层编码格式 ZIPLIST/PACKLIST. os: 紧凑列表其实要讲可以深入到源码级别,这里只是点到即止。深入源码分析,出门右转各位大佬博客,这里暂时先简单写,详细分析下次一定!........... <链接: _____先挖个坑______>
1.紧凑列表是什么?
紧凑列表顾名思义元素存储紧凑的列表 -- 列表元素存储在一块连续的内存空间内。
2.紧凑列表解决了什么问题?
紧凑列表主要解决小数据高速读写的问题,因为数据被设计存储在一块连续的内存空间中,可以很好的利用局部性原理,比链式存储数据读取更快,因为预留了一定定量的空间,在一定长度下的数据追加也回比链表稍快.
ZIPLIST
1.ZIPLIST 整体结构
chat is nut,show ZIPLIST code. (先偷个图)
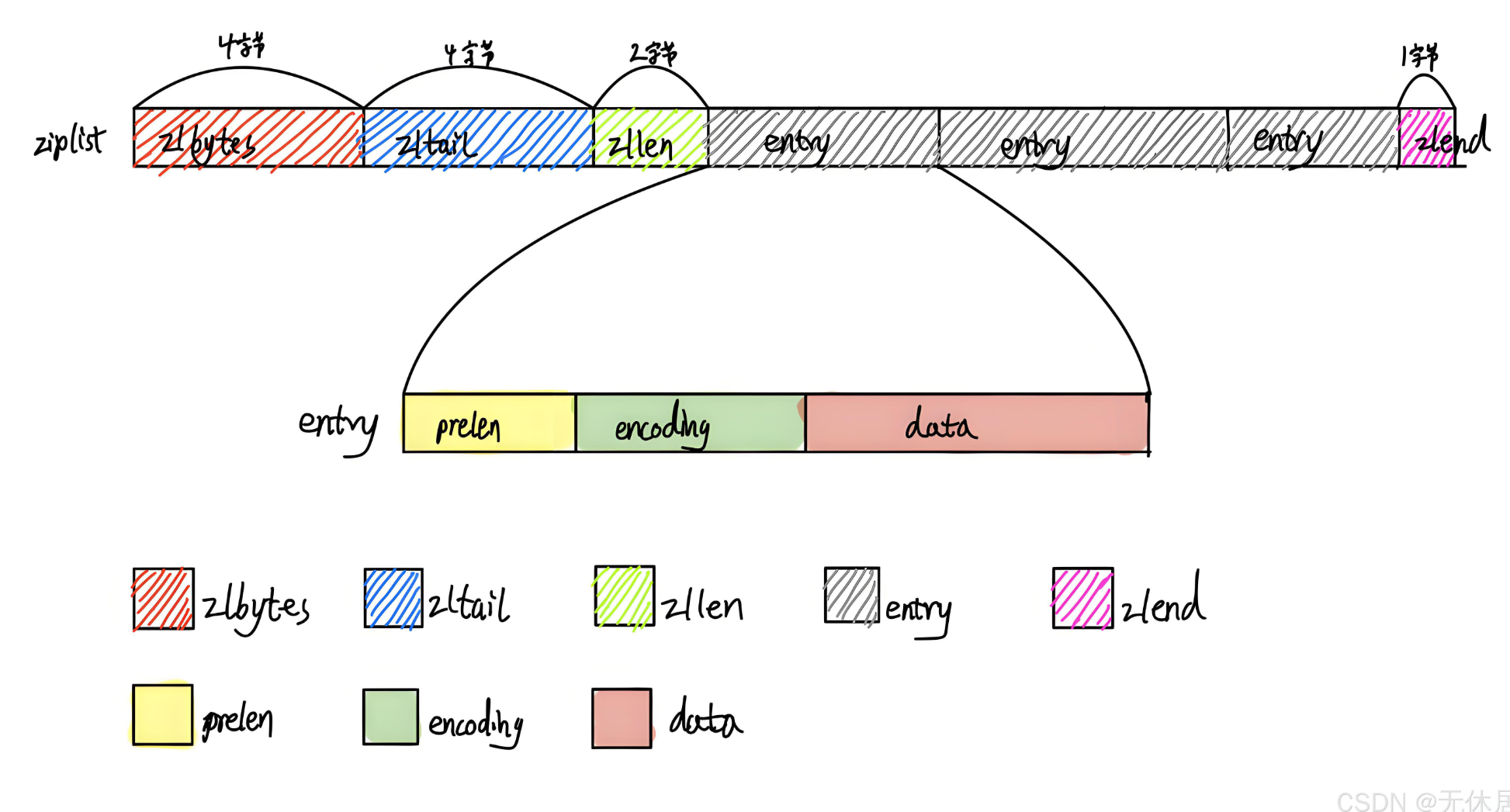
(OS:ziplist 第一直接是这个鬼东西应该也和embstr 一样有对应的struct sdshdr 这类的结构体对应定义的,但其实并没有... 而是调用一个newziplist(...) 创建一个ziplist truck 这个连续的内存块前一小段部分内存就就包含了这个ziplist truck 的元信息,trunk 最后1位长 是 值为0xff (255) 的magic number 表示这个trunk 的末尾,这个就有点像操作系统伙伴系统分配出的内存布局方式,也会在前后端上有对应的cookic)对应源码见下。
创建一个ZIPLIST trunk
unsigned char *ziplistNew(void) {
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
// 结尾标识
zl[bytes-1] = ZIP_END;
return zl;
}zlbytes: 这个truck 的长度有多少字长(ziplistnew() 出来的内存块有多少字节)
zltail:最有一个存储的元素相对这段内存的偏移值(相对zlbytes末尾偏移字长);
zllen: 有效entry个数,元素存储个数。0 - 65535,超过65535个时用0表示,redis 在解析这个值时发现是0 就会遍历整个trunk 去统计设计存储元素个数,因为不知道是 真的是0个有效元素还是超过65535了.
entry: 数据块【数据块里也含有数据块元信息 + 数据】
prelen: 上一个数据节点的长度,这样就可以通过偏移去寻址到前一个数据块
encoding: 数据块用的是什么编码格式
data: 数据
Zlend: end magic number,表示这个truck的末尾
2.ZIPLIST 节点结构
还是看上面偷的图
ZIPLIST 节点结构体定义
typedef struct zlentry {
// 前一个节点的长度,通过这个值,可以进行指针计算,从而跳转到上一个节点
unsigned int prevrawlen;
unsigned int prevrawlensize;
// entry 的编码方式
// 1. entry 是 string,可能是 1 2 5 个字节的 header
// 2. entry 是 integer,固定为 1 字节
unsigned int lensize;
// 实际 entry 的字节数
// 1. entry 是 string,则表示 string 的长度
// 2. entry 是 integer,则根据数值范围,可能是 1, 2, 3, 4, 8
unsigned int len;
// prevrawlensize + lensize
unsigned int headersize;
// ZIP_STR_* 或者 ZIP_INT_*
unsigned char encoding;
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;对应参数说明见上,这里变化比较多的编码格式标志位:
2.1 ENTRY - CODING :
(OS:这个鬼东西,网上有很多什么 前面 6位二进制编码后 后面一堆 什么 pppppp | qqqqqqqq .... 的鬼玩意,然后再一同鬼扯,其实只需要看前八位码就好 - coding 编码大致分为两类 整数编码/字符串编码)
大致规律可以用这句话概括:高位前两位其中有一位是0那就是字符编码(00、01、10)前两位高位是 11 是整数类型编码.除非研究特别深入否则暂时不需要知道前八位之后的编码表示什么意思.
这里还是偷大佬的图:
字符串编码

整数编码
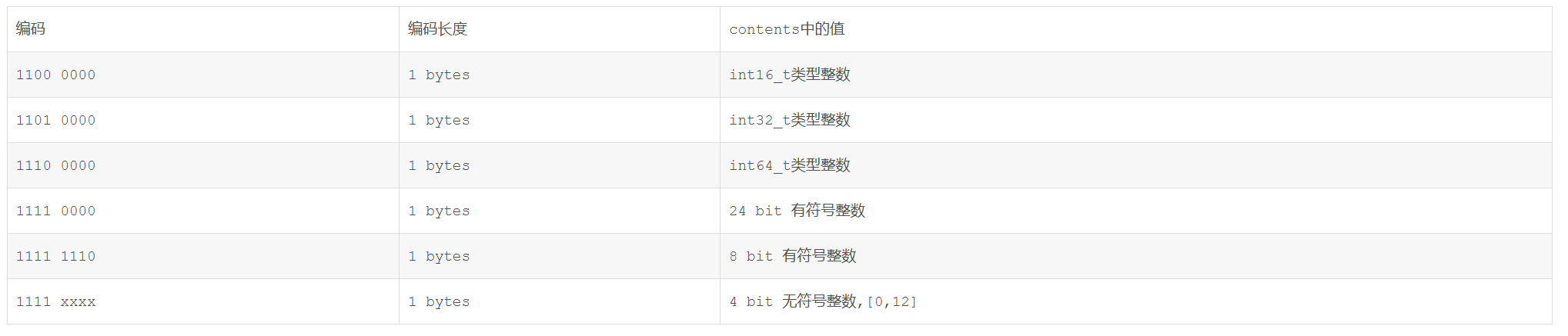
这里只说明 1111 xxxx 这个东西:
xxxx 的取值范围可以是 0 - 2 ^ 4 也就是 0001 - 1101 这四位表示实际的数据在是 1-13 【这是redis 规定的,至于为什么这里暂时不去研究】 而实际对应大的元素真正数值是 [1-13] - 1 = [0 - 12] -- 直接存在编码空余位里,就不用再去使用专门的data 块去存储数据(也就是没有数据块),可谓讲空间利用到了极致。
3.ZIPLIST 数据查询
这里只关心查询数据的两个操作
3.1 查询数据总量
ZIPLIST 中定义有记录元素个数的属性成员llen 但llen 是无符号的 unsigned short 占2字节最大值是 2 ^ 16 = 65535 所以当存储的值超过65535 时 这个值回变为0,这时候redis 判断这个值若为0 就会去遍历方位整个ZIPLIST trunk 并统计有效trunk个数并返回真正的数据总量.所以当数据小于65535 的时候效率时O(1) ,大于65535时是 O(N)
3.2 查询指定数据的节点 LRANG
ZIPLIST 没有对应属性成员记录该值,所以只能遍历真个trunk O(N)
3.3 ZIPLIST数据更新
这个得分两种情况说明 因为prelen 因为插入数据的长度超过1(8bit - 0-255[10 - dec])个字节表示的长度范围是会膨胀为5个字节的prelen。
case old prelen -> new prelen < 255 字长:遍历找到需要更新的节点O(N),只更新这个节点的数据和跟后继结点的prelen - O(1),并作节点内的数据腾挪 O(N),时间复杂度是O(2N) 化简:O(N)
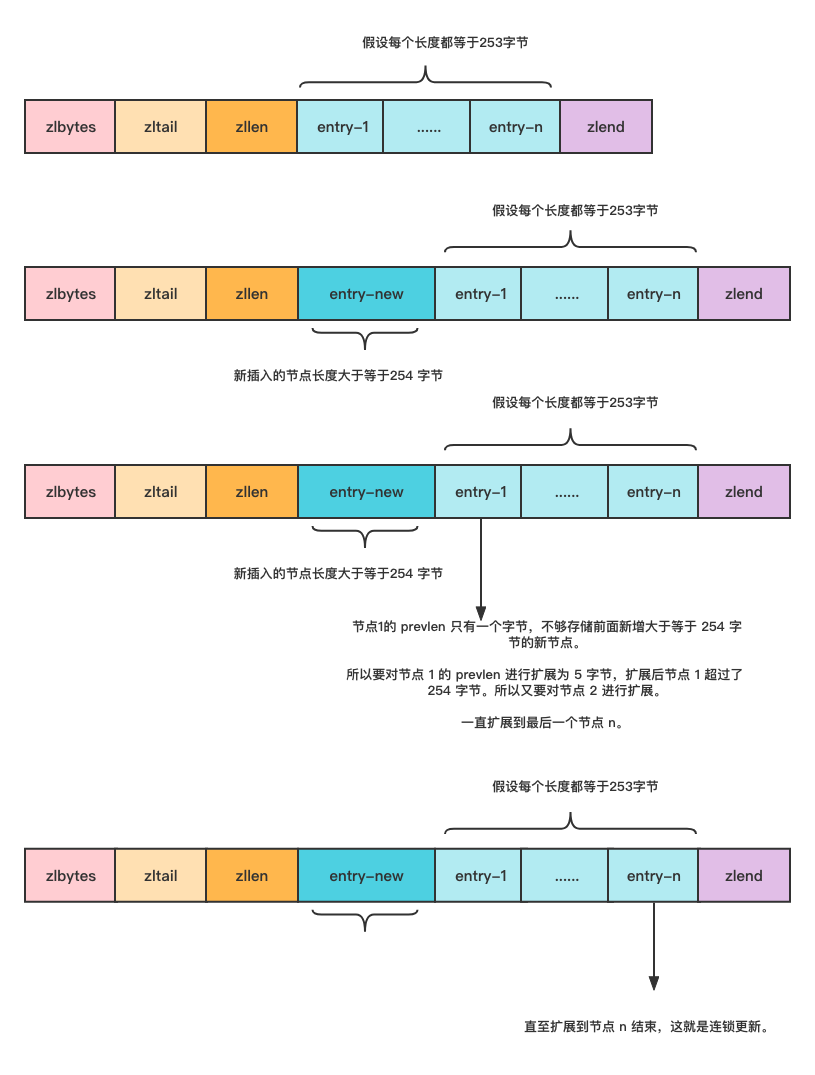
case old prelen -> new prelen > 255 字长:这时后就会出现连锁更新问题,也就是ZIPLIST性能不稳定的原因.当更新写入的数据导致当前节点实际长度超过255字节,上一个节点的prelen 用一个字节去记录后继结点的长度就会发生值溢出,所以只能升格为5个位长的prelen 才能去记录得下当前更新节点的长度,导致前驱节点内存占用膨胀,再次产生数据腾挪,这样时间复杂度就变为了O(N^2)(OS1:ver6.2 已经优化位O(N))
偷个图下面是连锁更新的示意图:
PACKLIST
一句话概括连锁更新极端情况下链表里有不少长度254是的节点,有个大于255长度 entry 要插入进ziplist这时候新插入节点的后继节点prelen会由于新插入节点长度大于255 值溢出而升格成用5字节的变量去存储新节点长度,导致这个后继节点长度也突破了255进而又更新下一节点...就这样炸了... 罪魁祸首其实就是prelen 是可变长度导致的连锁更新.
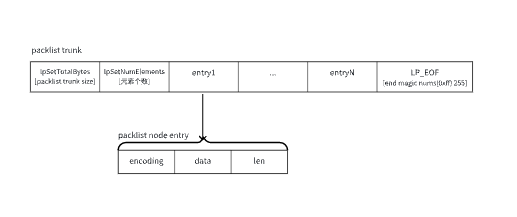
偷个大佬的图
PACKLIST 如何解决ZIPLIST 连锁更新的问题?
看上面偷的图,然后再看下面偷的图,看完且听我say...
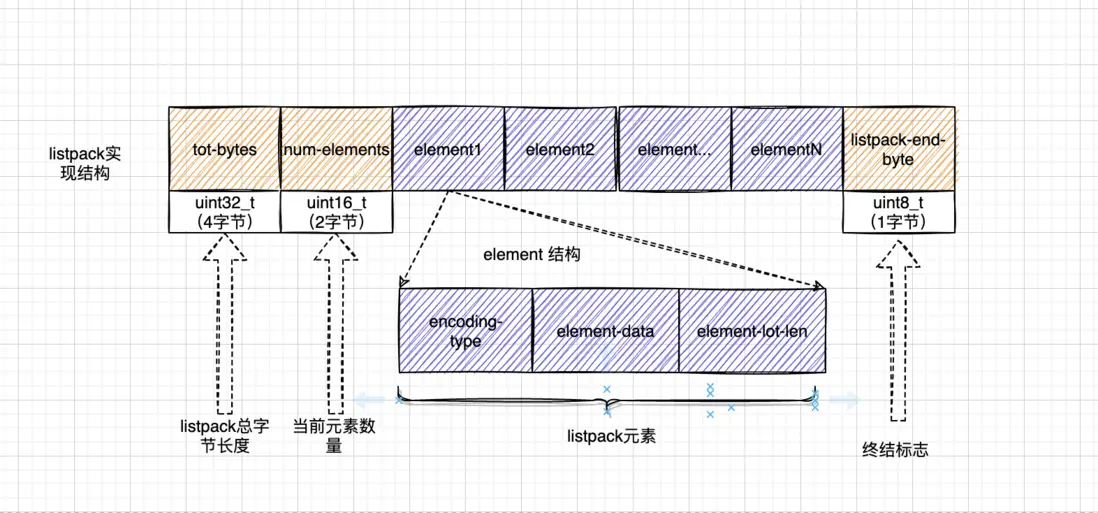
listpack node 布局示意图:
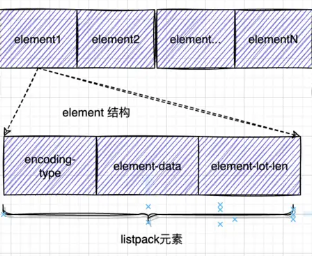
listpack node element-total-len 编码结构示意示意图(element-total-len 采用大端字节序存储编码信息):
整数编码
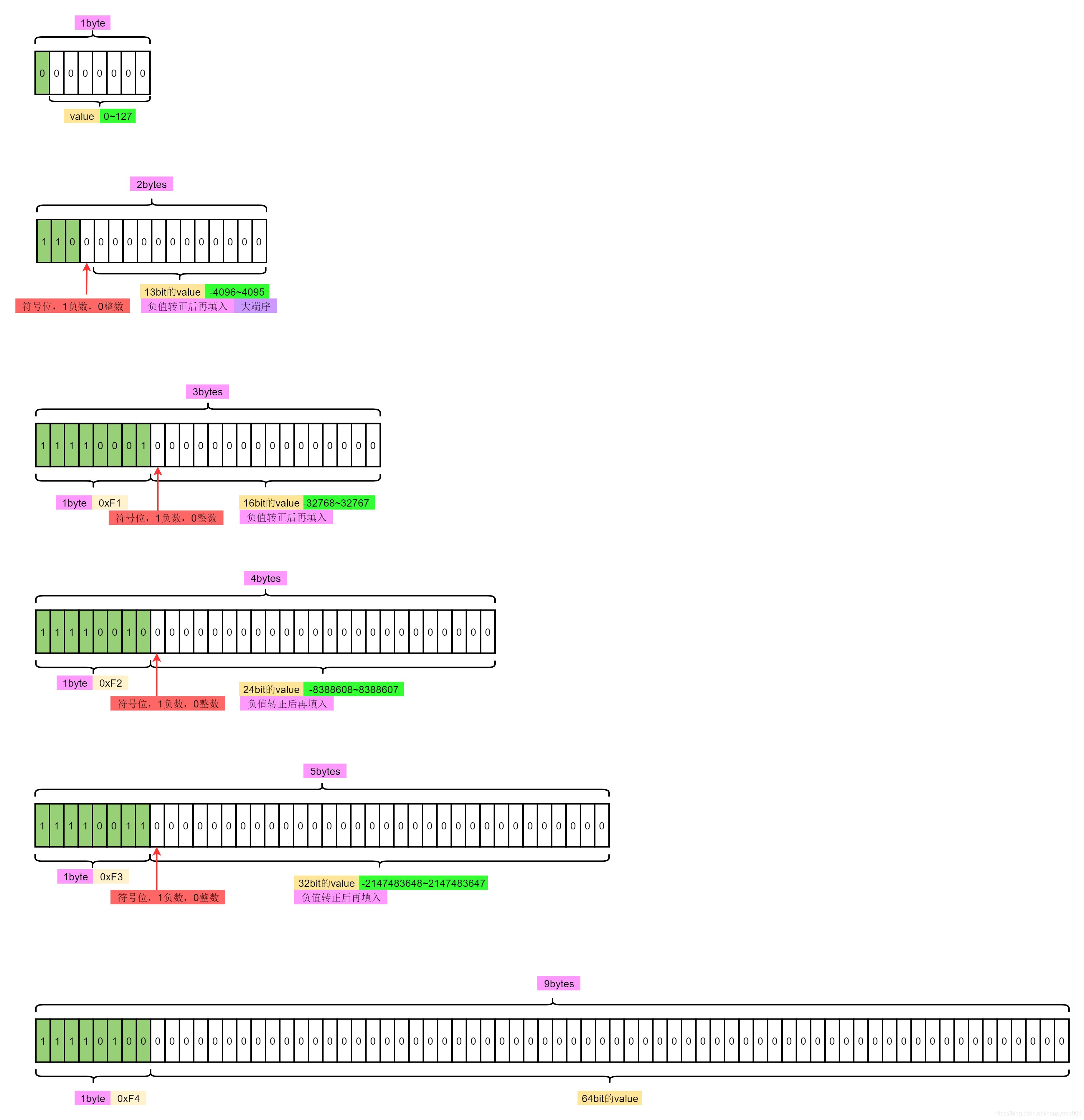
字符编码
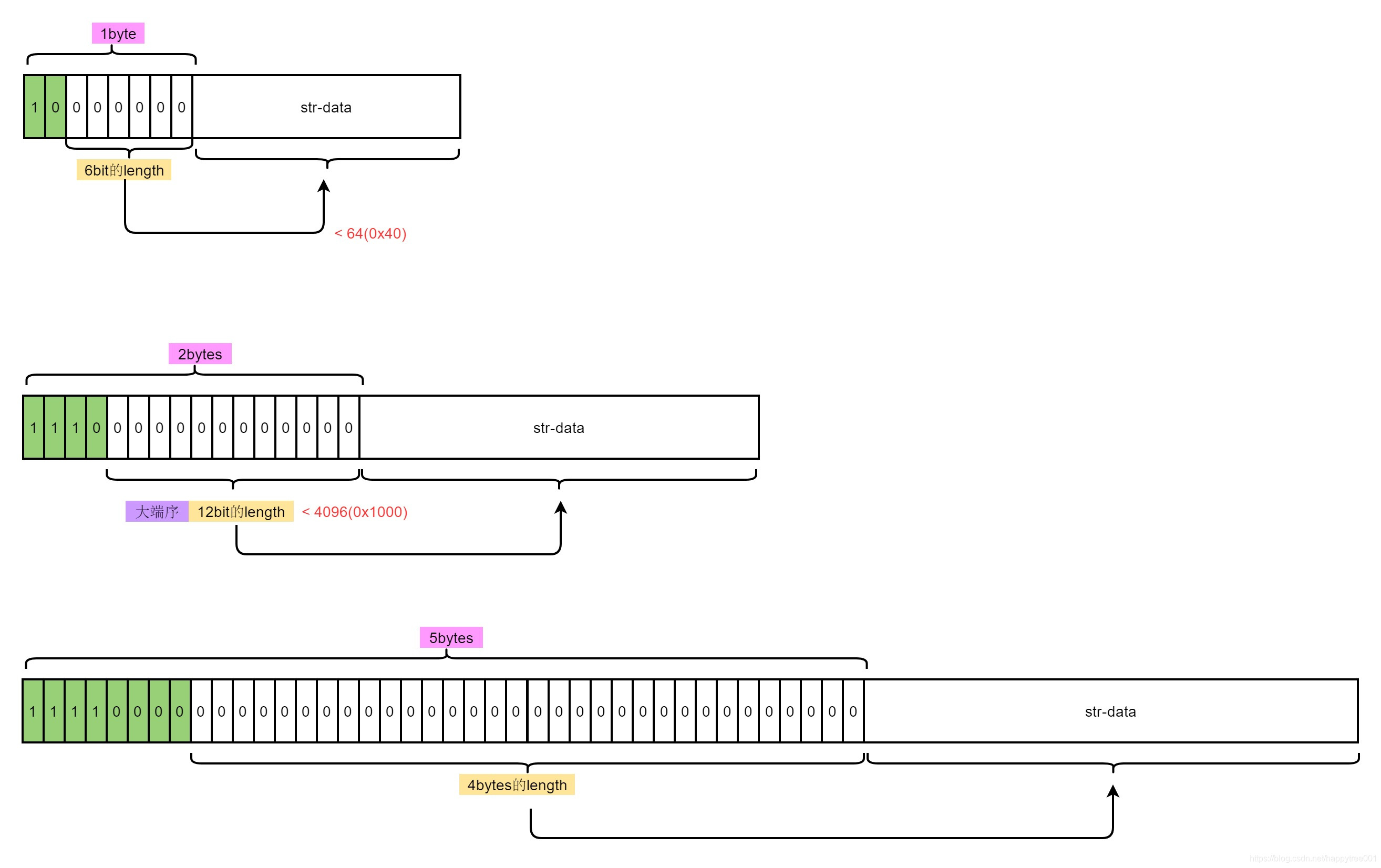
ANSWER:
(OS : 其实说是解决了,也算解决了,就是把prelen 变长特性给干掉而已,然后原来把原来记录前驱节点的属性后移到数据段后面也就是着么个布局 <encoding-type><data><element-total-len>,然后把原理记录前驱节点长度改成记录当前node节点长读,把这个属性后移是为了维护原来ziplist 可以逆序遍历(从右向左)的功能可用)
通过修改节点结构和修改节点元信息记录信息去解决.就是使原来prelen 可变长变为分类定长,这样就不会出现因为数据节点占用空间膨胀导致连环更新的问题。
修改后如何维持原来节点支持双向遍历访问的特性?
把prelen 这本变量改为element-total-len 之后将这个变量的存储区放数据节点的末尾形成这样的布局:<encoding-type><data><element-total-len>,让后存element-total-len 个存储字节序改成大端字节序,地址从高到低:前7位存数据长度低0-3位(2^7 = 128) 第八位地位存数据 0 / 1 表示前面还有没有数据需要解码 一直重复这个步骤,知道遇到第八位是0表示读取完毕,这是侯就可以知道当前节点的数据长度那么 就可以通过当前节点末尾地址 + element-total + 就可以让指针偏移到前继节点的末尾地址...这就完成了一次前继节点的访问.
偷个大佬的图,element-total-len 编码示意图
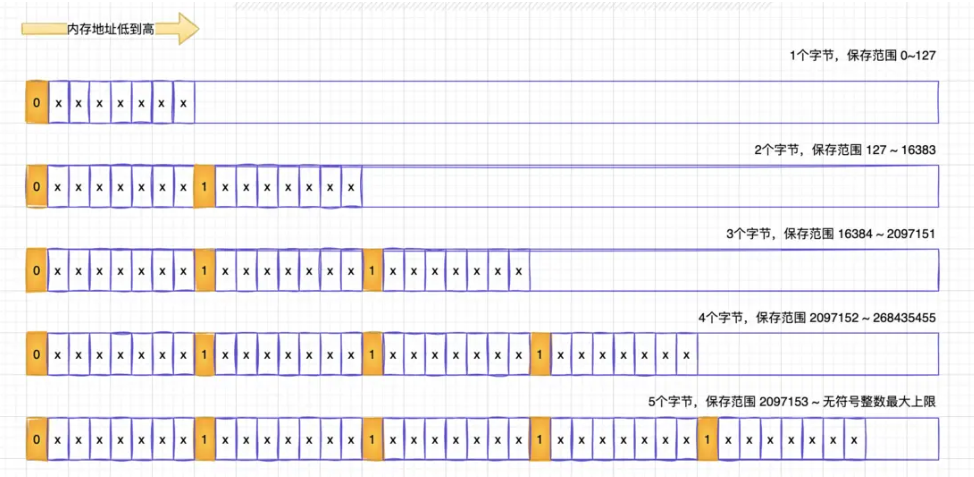
具体解析看这篇:Listpack 如何解决连锁更新|ZklMao-Space
Interview
1. ZIPLIST有什么优点?
因为是数据都存储再整段的连续内存中,重复分利用了局部性原理,访问命中率更高,更快
编码格式精妙紧凑,节约内存
创建节点是只需要分配一次内存空间
2. ZIPLIST是怎么压缩数据的?
(OS:我不认为这鬼东西叫压缩,而叫紧凑,因为只是最大化的利用了比特位级的存储空间而已,并没有出现严格意义上的押送,也就是没有对输入信息进行信息熵上的变换压缩,即输入的数据信息量没有变化,信息表示载体也没变化...[可以参考哈夫曼编码 - 压缩])
数据结构各成员设计紧凑,定义的结构体中,编码数据是按位存储的,输入数据是较短的整型数据时甚至可以不存在数据块,将值直接存到编码类型空余位中.
数据排布紧凑,数据存储在整块内存段中的,数据首位相接,中间没有相对来说的内部间隙.
3. ZIPLIST下List可以从后往前遍历吗?
[tip] ziplist entry struct : <prelen><encoding><data>
ziplist 成员定义中有一个zllen 成员记录的成员数量那这个值取做指针地址偏移就可以得到最后一个节点位置之后进到节点成员中进行编码解析可以得到....[ -- 看下面 --]
可以因为节点结构体成员定义中有一项prelen在每个数据节点的头部,同过这个长度数据做指针(地址)偏移即可访问到前一个数据.
4. ZIPLIST下List如何从前往后遍历吗?
在数据节点成员定义里有一个encoding,这个编码就包含了这个节点的数据类型和数据长度.拿到这个就可以做指针地址偏移跳到下一个节点.
5. 在ZIPLIST数据结构下,查询节点个数的时间复杂度是多少?
zllen 是两字节无符号整数 (uint16)
zllen > 2^16(65536) 时因为数值溢出,会直接记为0 不知道长度,所以需要遍历O(N)
zllen < 2^16(65536) 时没有溢出,数值准确,直接可以返回O(1)
6. 压缩列表插入的时间复杂度是多少?
正常情况不存在极端情况也就是相邻数据节点长度都离prelen 升格位 5字节很远的情况下是O(N) --- 插入数据要做数据腾挪,向数据插数据后是一样的.
极端情况O(N^2) 因为prelen 升格为5字节,这个会产生链式反应,这样一趟下来会产生因为节点膨胀下的数据腾挪和一次因为新数据插入带来的腾挪,综合算下来是O(N^2)
7. 连锁更新是什么问题?
看上面问题6第二部分的回答....

