
这篇是LIst 萌新篇,don't cry maid ...
1.List 是什么?
顾名思义,List 是链表,在Redis 中的List 表现出双向链表的的特性,可从首尾端进行链表的相关操作,比如读,写(加节点).
1.1.List 有什么限制
List 最大元素个数最大限制为 2^32 - 1 个 (链表中有一个记录链表的属性成员len,这个len 在旧版最大字长是4 所以存储极限长度就是 2 ^32 - 1), 在新版本中变为 2^64 - 1 原理同上。
2.List 适用场景
这个根据List 本身数据结构特性触发(队列不可随机访问只能按正向顺序或者逆向顺序操作),可以作为数据队列/消息队列等...
3.常用操作
看图说话:
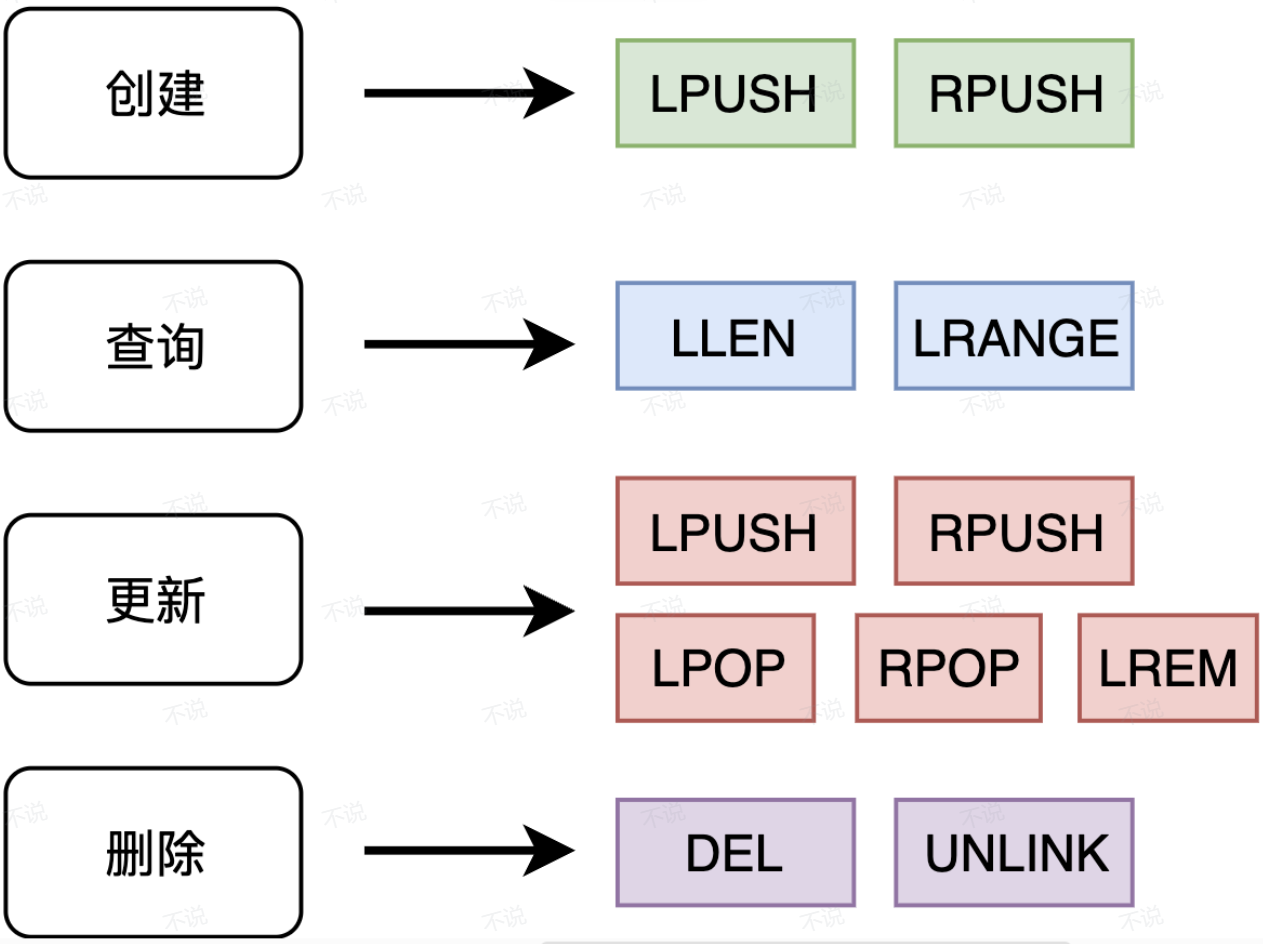
LLEN key: 获取队列长度
LRANGE key start_index end_index 查询区间[start_index,end_index] 的元素【start_index,start_index 为符值时表示从右边删除(- 1 表示倒数第一个-- 右边第一个,-2 ... -n 以此类推)】
LREM key n value : 从左向右删除 n 个 值等于 val 的元素.【注意 n = 0 则删除所有等于 指定value的元素】
DEL key1 ke2 key3 ...: 阻塞/同步删除 输入的key... 和对应的数据
(4.0引入)UNLINK key1 key2 key3 ... : 异步删除 输入的key ... 和对应的数据. 【这里会涉及到一个大key 删除问题,key 里的数据很多,用DEL 同步删除会导致业务阻滞/堆积 ...所以使用 unlink 删除,其工作原理和文件系统中的引用计数一样,将这个key 引用删除之后由后台线程稍后回收脏内存块】
4.List 底层实现
这里还要偷2个图:
Before version 3.2
3.2 前 List 由两种编码按格式分贝是ZIPLIST(压缩链表)、LINKEDLIST (标准链表 - 双向链表)
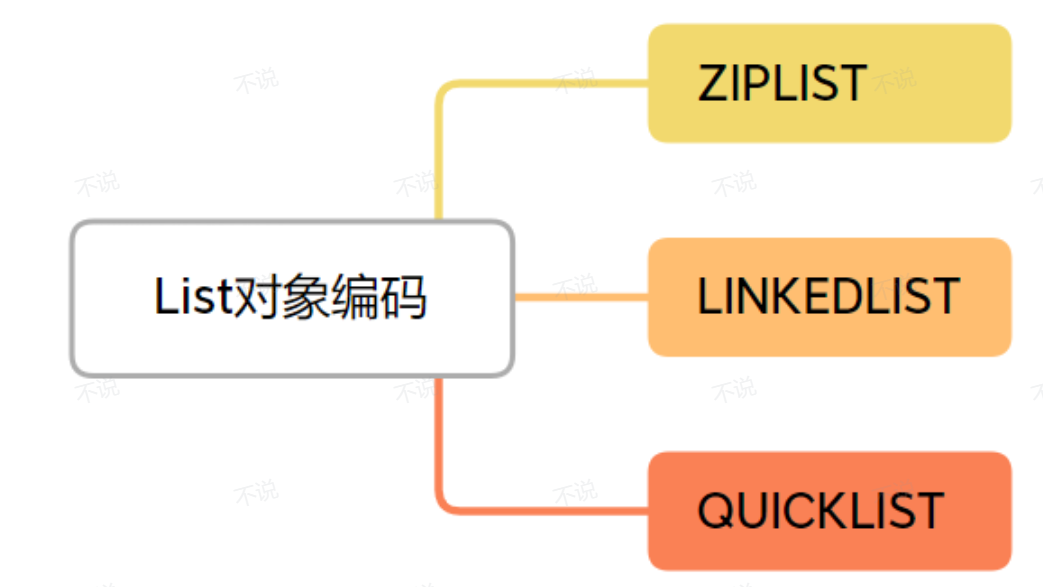
After version 3.2
3.2 之后由于ZIPLIST、LINKEDLIST 在当前业务场景下很容已触发极端情况导致性能低下,所以需要重新设计新编码格式以改善当前情况。所以QUICKLIST 横空出世.[ZIPLIST 数据多了之后因为操作数据带来的数据腾挪代价会增大(因为ZIPLIST是一个用数组表示的链表),LINKEDLIST 数据节点多了之后其节点本身的内存开销就很大了],QUICKLIST整合了二者的长处进一步优化业务效率.具体有点是什么?看下面细细道来:
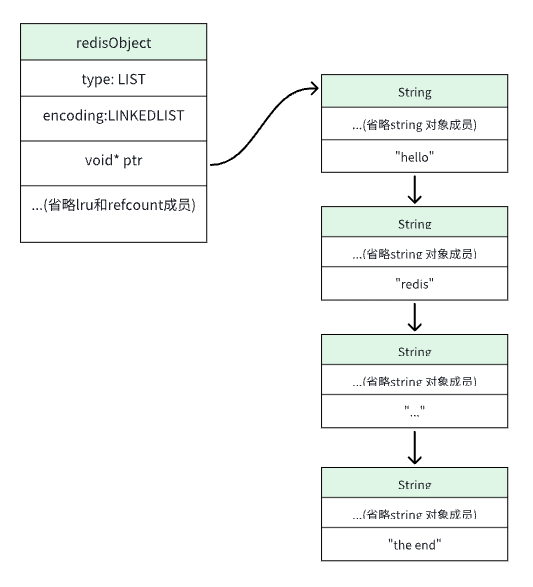
好的这里我们和并一起说... 我们先逐个说清楚ZIPLIST、LINKEDLIST的底层结构是什么样的在说QUICKLIST... 这里提前存入一段数据: "hello" "redis" ... "the end" 共N个 value。
4.1 ZIPLIST
ZIPLIST 结构示意图如下:

看上面的结构图可知,ZIPLIST 结构也类似于 embstr 的编码套路,也是redisObject 数据指针指向一个连续内存块,这个内存块以连续数组的形式存放着用户存入的数据.
4.1 ZIPLIST 使用条件
既然LIST 有三种编码格式,那什么时候用ZIPLIST 呢?
使用ZIPLIST 条件有二且必须都满足:
存入的 value 长度strlen(value) 必须小于64 字长;
存入的value总个数最大只能到512个.【这不是编码格式ZIPLIST的限制,是上层LIST的限制 】;
ver3.2前任一不满足则转换为LINKEDLIST;
3.2 之后怎么变换再说.
4.2 LINKEDLIST
LINKEDLIST 结构图如下
接上回4.1 如果上面ZIPLIST两条件 有任一不满足则LIST 会使用LINKEDLIST 编码格式。
4.3 QUICKLIST
这里偷个图...
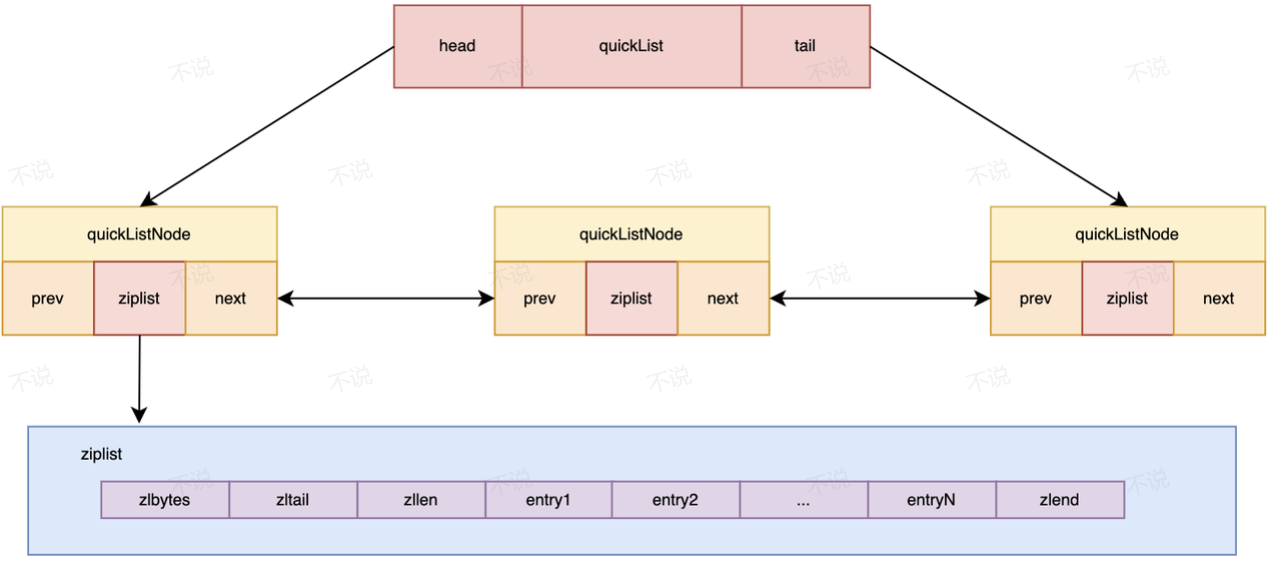
看图回答3.1中的问题 ”QUICKLIST整合了二者的长处进一步优化业务效率.具体有点是什么?"
ZIPLIST 优点是数据都存在整段连续的内存中且限制长度小于64字节,与Redis底层内存分配器对齐充分发挥局部性原理,随机访问速度快.
LINKEDLIST 有点是改进了ZIPLIST 的缺点链表删除数据只需要O(1) 不需要作数据腾挪。
单但二者都有各自缺点,这些缺点在极限情况下回十分影响业务:
ZIPLIST 数据量大了之后修改数据产生的腾挪代价回变大.
LINKEDLIST 数据量变大后由于链表特性,数据节点操作效率回越来越低
LINKEDLIST 数据量变大后由于链表特性且每个节点是string对象 ,节点本身的内存开销本身也逐渐增大.
综合上面二者优缺点分析,Redis 设计出了QUICKLIST.QUICKLIST 结合了上面二者的有点,并有效个改善的上面二者的缺点具体结构看图,其就是用ZIPLIST作QUICKLIST 链表的节点, 用LINKEDLIST 的结构取组织若干个ZIPLIST节点数据去存储; 【这样在数据量少的时候直接用ZIPLIST去存储数据充分发挥出了数组结构的随机访问快的优势,当数据暴增时,新加入的数据可以存在新开辟的QUICKLIST节点上这又充分发挥了链表结构数据删除快的有点,且ZIPLIST 的内存效率也比string对象 要高效一些.
4.3 ver7.0 后ZIPLIST 优化
ZIPLIST 由于本身(用数组存数据)数据组织的原因存在连锁更新问题,所以在7.0 后使用LISTPACK(紧凑型列表)编码取代了ZIPLIST 而其中是怎么优化的,且听下回分解....
5.总结
LIST 是Redis 中的一个双端队列对象,编码格式在3.2前有ZIPLIST、LINKEDLIST,3.2 之后引入QUICKLIST;QUICKLIST是ZIPLIST和LINKEDLIST二者的结合体,QUICKLIST 编码格式改善ZIPLIST 连锁更新问题,LINKEDLIST 节点 在大量数据存储时 string 对象本身内存专用较大问题,7.0 只有用PACKLIST 替代了QUICKLIST中的ZIPLIST,QUICKLIST是ZIPLIST 的改进版本...
6.interview
来到了 List interview 环节...
1.LIST 是完全先入先出吗?
Redis List 底层实现是双向链表,双向链表是可以在首位作读写操作的。从命令也可以看出,L/R PUSH L/R POP
2.怎么获得LIST指定区间的数据?
LRANG key startInx endInx : startInx, endInx >= 0 表示从左向右,startInx, endInx < 0 表示从右向左 倒数第一个第二个....
3.LIST 如何移除指定数据?时间复杂度是多少?
LREM key(list name) n val : n = 0 移除所有,n > 0 移除 n 个 值等于 val 的元素
链表删除元素只需要unlink、free/recycle 两步,用大O 表示法是O(1)
4.LIST 底层编码方式?
redis 3.2 是一个分水岭版本
version 3.2 前
有两种编码方式:ZIPLIST、LINKDEDLIST
version >= 3.2
QUICKLSIT 一统天下: 加入QUICKLIST,QUICKLIST 是ZIPLIST 和 LINKEDLIST 的组合体。就是存在三种编码方式:ZIPLIST、LINKEDLIST、QUICKLIST
version >= 7.0
PACKLSIT 取代 QUICKLIST中的ZIPLIST --- PACKLIST 解析见下篇 ....
5.LINKEDLIST 编码下查询节点个数的时间复杂读是多少?
chat is nut,show redis source code.
typedef struct list {
listNode *head;
listNode *tail;
void (dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void ptr, void key);
unsigned long len;
} list;listNode *head: 指向链表头的指针。listNode *tail: 指向链表尾的指针。void (dup)(void *ptr): 用户接口,提供拷贝函数,用于复制列表中的元素。void (*free)(void *ptr): 用户接口,提供节点内存释放/回收函数,用于释放列表中的元素。int (*match)(void ptr, void key): 用户接口,提供节点匹配/查找函数,用于比较列表中的元素与给定的键。unsigned long len: 表示链表的长度。
LINKEDLIST 编码结构体内定义有 len 成员属性用于记录链表存储元素个数,复杂读是O(1)

