
这篇主要分享Redis 多机部署。大概分为主从集群、哨兵模模式、切片集群.
什么是主从集群?
Redis主从复制模式是一种数据冗余和高可用性的解决方案。在这种模式下,一个Redis实例作为主节点(Master),其他实例作为从节点(Slave)。从节点会复制主节点的数据,并在主节点出现故障时提供备份。
用法:单示例无法满足业务要求,一般做读写分离,主写,从读
主从模式如何同步数据?
主从同步数据有三个情况下会发生:
部署完成,正常运行的的增量同步,redis 周期函数定时replicationCron(…) 函数检查从机会检查与主节点的链接状态。如果断开则连接,正常则向主节点发送psync 命令拉数据,这里会出现两种同步形式:
case 1: 主机和从机之间的数据偏移过大(大于偏移buffer容量),主节点会触发RDB,并讲当前RDB文件发送给从节点,后序若有写命令进主机,则会追加到replication_buf中,等RDB文件发送完成后跟着发送给从机做增量同步
case 2: 二者偏移量小于偏移同步buffer 容量,使用增量同步讲命令直接发个从机,从机命令重放同步数据。
第一次连接 发送psync,主机触发RDB,发送RDB文件,发送replication_buf 命令
掉线一段时间后重连…看上面case1
如何部署?
从机cli : replicationof master_ip master_port
查看节点信息 info replication
缺点:故障后需人工做故障转移,一般配套哨兵模式使用
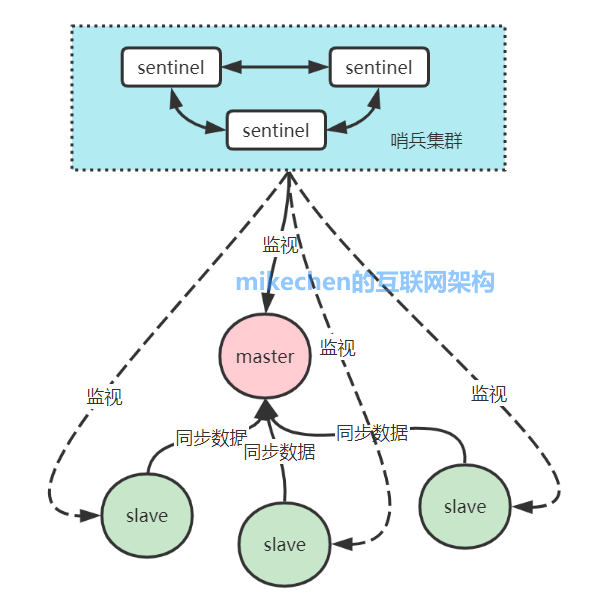
什么是哨兵模式?
Redis哨兵模式是一种高可用性解决方案,它可以在主节点出现故障时自动进行故障转移,并将一个从节点提升为主节点。给主从模式设计的分布式自治方案,单主从模式无法自动做故障转移缺点。
偷个大佬的图
如何部署?
创建一个哨兵配置文件sentinel.conf:
port 23333
daemonize yes
pidfile /var/run/redis-sentinel.pid
logfile /var/log/redis/sentinel.log
dir /var/lib/redis-sentinel
sentinel monitor mymaster 127.0.0.1 3666 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
sentinel parallel-syncs mymaster 1启动哨兵节点:
redis-sentinel /path/to/sentinel.conf大致工作原理
这里先说这个一个配置项 quorum :
这个配置项用于哨兵头子选举,哨兵头子候选人只有拿到 >= quorum 才会正式上任成为哨兵集群头子,否则继续选举投票,这个值设置必须大于哨兵集群节点数/2 否则无效设置。
选举哨兵头子:基于Raft 算法投票选出哨兵头子。
哨兵节点是一个单独的进程示例,哨兵可以和数据节点再同一台主机中,哨兵节点每1S会给哨兵头子和其他哨兵节点还有监控的redis 数据节点发送ping 心跳,超时不回复pong 或者恢复 错误消息该节点就会被标记为主观下线,之后回合其他哨兵节点(包括哨兵头子)询问该节点情况,返回下线次数超过 N/2 + 1 (过半数) 则讲该节点标记为客观下线。有发现掉线的哨兵节点发起故障转移,也就是发起数据主节点选举和给故障转移的从节点提供主节点IP,让从节点连接新节点,若过段时间后崩溃节点重新上线哨兵头子会发出slaveof 命令让重新上线的节点便问从节点,具体故障转移流程如下:
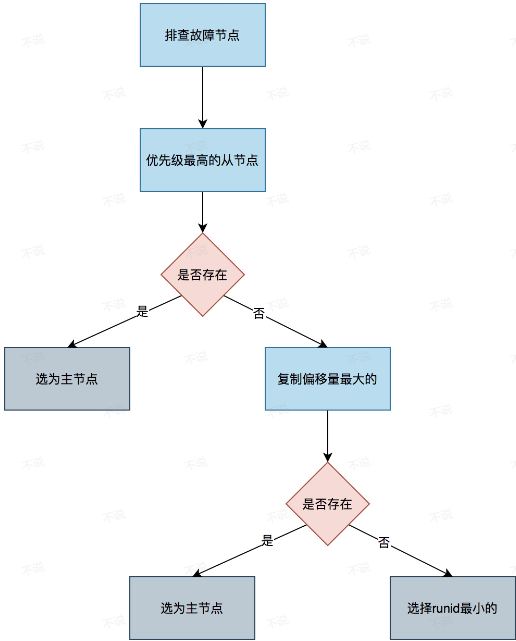
1.通过网络延迟请款过滤延迟高的主机
2.通过配置文件redis-sentinel.cnf 或获取节点优先级 replica-priority ,值越小优先级越高,选优先级高的做主数据节点,如果此情况不满足,走步骤三
3.(数据复制数据最完整的)从这批候选主机中找数据复制偏移值最大的那台主机(主机会给从机同步偏移量值,从机再同步数据完成后会同步偏移量,当同步完成量偏移值相同,可以理解为数据版本号...),让这台主机成为主节点,如果不满足条件进入步骤四
4.找runid 最小的节点做主节点(runid 时每台节点启动时redis随机分配的一个值).
什么是切片集群?
Redis集群模式是数据量过大时的一种数据存储策略,通过哈希函数确定数据存储的哈希槽位,集群节点存储定义分片的数据。
如何分片?可以手动,或者有集群自动分片。
如何部署
常见几点文件夹,文件夹下有redis.cnf 配置文件拷贝:
开启 cluster-enabled 字段 yes
port 7001
cluster-enabled yes
cluster-config-file nodes-7001.conf
cluster-node-timexout 5000
appendonly yes
daemonize yes
pidfile /var/run/redis_7001.pid
logfile /var/log/redis/redis_7001.log
dir /var/lib/redis_7001在文件夹下启动
redis-server /path/to/redis.conf可以使用下面几个命令组建集群:
redis-cli --cluster create ... --cluster-replicas id_num
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1redis-cli --cluster add-node ip:port ip:port
redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000cluster meet ip:port
redis-cli cluster meet 127.0.0.1:7006集群哈希槽
看图
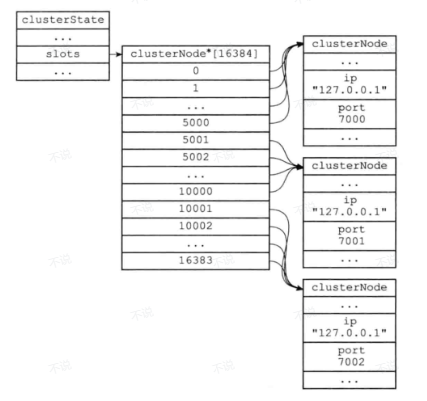
Redis是用哈希槽来管理数据分片,Hash槽就像是划分了很多个槽位,不同请求会分流到不同的槽位,以实现压力均摊的效果。
一个 Redis Cluster包含16384(2^14)个哈希槽,存储在Redis Cluster中的所有Key都可以通过Hash算法(CRC16 算法)算出一个Hash值,然后对16384取模,从而关联到某个槽,而每个节点负责一部分槽,Key算出来在哪个槽,就应该去负责这个槽的节点进行交互。
//from redis 5.0.5
```c
#define CLUSTER_SLOTS 16384
typedef struct clusterNode {
...
unsigned char slots[CLUSTER_SLOTS/8]; /* slots handled by this node */
int numslots; /* Number of slots handled by this node */
...
} clusterNode;
```大致工作原理
分片后每个节点会负责存储经由哈希函数计算出哈希值hashVal 在经过 取模 2^14=16384 映射分配过来的kv,在查询时,每个节点回村有存储有所有节点负责分片ID的ID映射表,通过计算这个key 的hashVal 做同上的写入映射计算就可找到对应的主机节点,如果时本机,则进存储词典查询反值,否则返回存储该kv对的节点信息.

