
这篇分享的是一条语句从执行层拿到连接层数据传递的SQL语句开始,一句SQL再MySQL执行层中是如何被执行的。
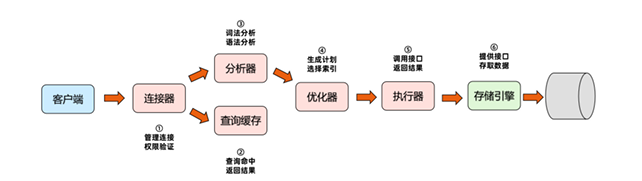
MySQL 三层架构 -> MySQL 逻辑架构
这里我们限定,MySQL 查询语句未命中查询缓存,需进行剩余流程才能获取查询结果;这里我们之说MySQL 5.7 和5.7 之后的版本。因为5.7 加入了索引下推特性,优化了范围查询的回报流程。一条未命中query buffer miss 的查询语句会经过大概五步才能获取到查询结果:
再开始前: MySQL 会做权限鉴定,连接的时候会检查认证口令是否正确,正确之后读取登陆用户权限配置记录,这条配置记录,以后都会用到,检查这条语句是否有权限操作这个表。
Step1 建立连接,检查登陆口令
这步没啥好说的
Step2 查询query buffer
把输入进来的SQL语句哈希,查query buffer, 查到就反数据,查不到进下一步
Step3 解析SQL 语句
1. SQL 分析器
- 词法分析(断句得词): 根据一定规则拆分输入进来的SQL语句,检查这些 拆分后额token 是否是再SQL定义的keyword 表中。
- 语法分析: 检查是否符合语法。
Step4 指定执行计划,执行
(os: 这个有得说了...)
执行一条SQL 分三个阶段:
- prepare 预处理
- optimize 优化
- execute 执行
1.预处理器
- 检查用户操作权限,调用get_table_share()检查操作的表是否存在,检擦操作的列是否存在,将select * 中的* 扩展到表上所有列构建解析树。
2. 优化器
- 通过引擎结构向引擎获取引擎特性信息,操作表统计信息。
- 根据信息优化SQL语句制定合适的查询计划,比如重写SQL语句,根据引擎回应的代价表选择合适索引等。可以需要执行的语句前加explain 获得这条语句的执行计划。
这里用三条语句举例,优化器再索引上的优化:
a.主键索引查询 select * from info where id=xxx;
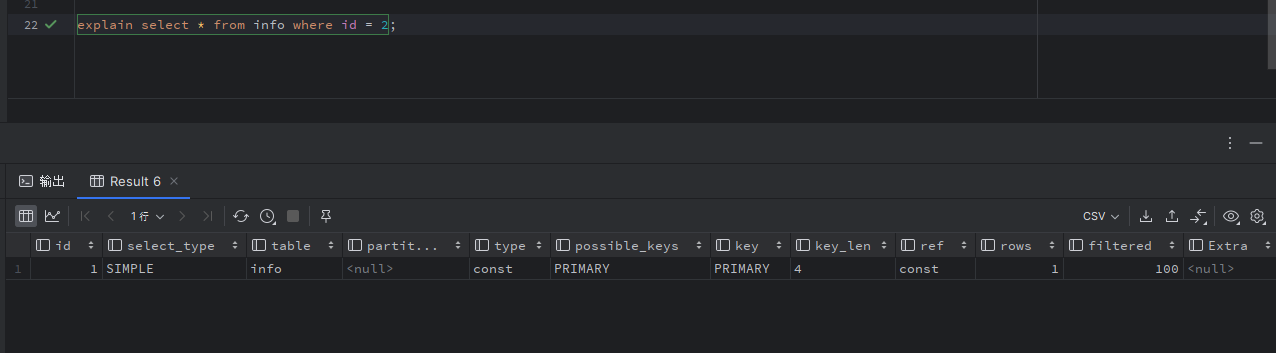
explain 表中type 列值为PRIMARY, 表示主键索引查询
b. 查询语句中没有索引可利用: select * from info where name=xxx; explain select *from info where name=xxx 查看执行计划:
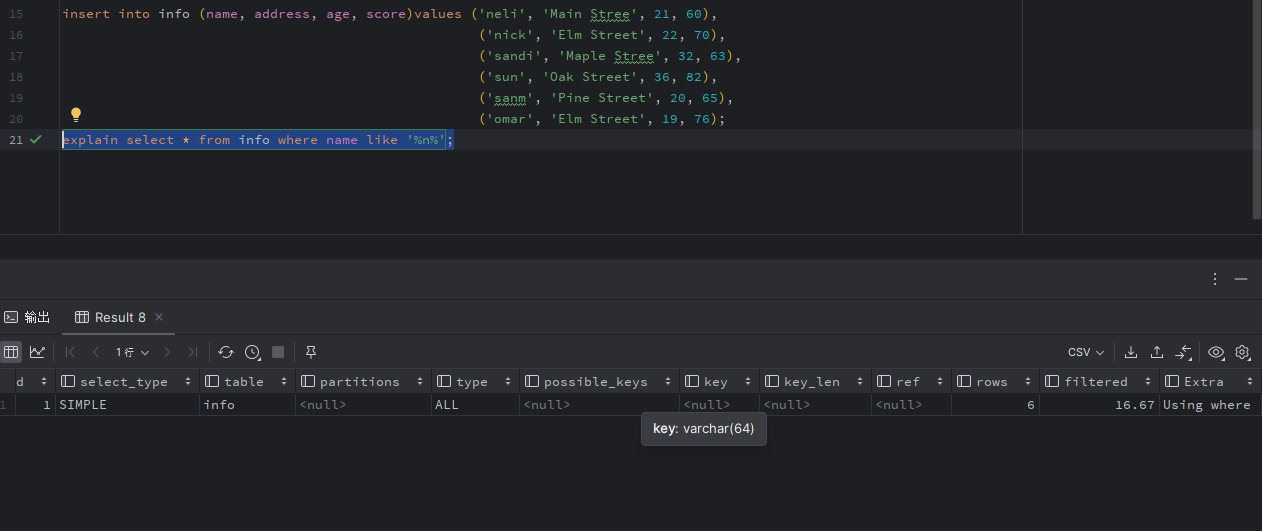
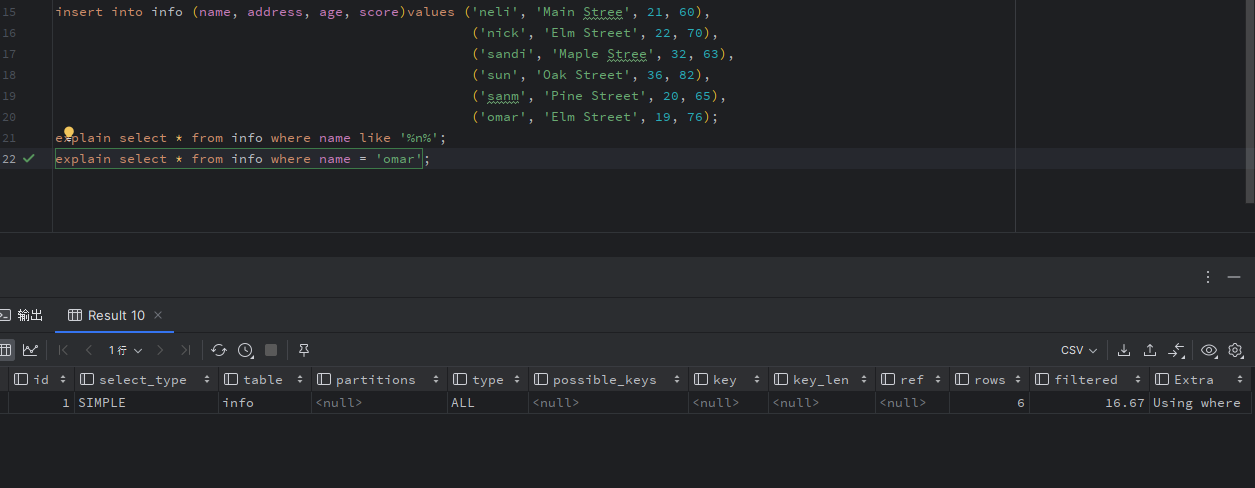
因为info没有为name 建立二级索引。这是后优化器只能选择全表扫描。explain 表中type 列值为ALL,表示全表扫描
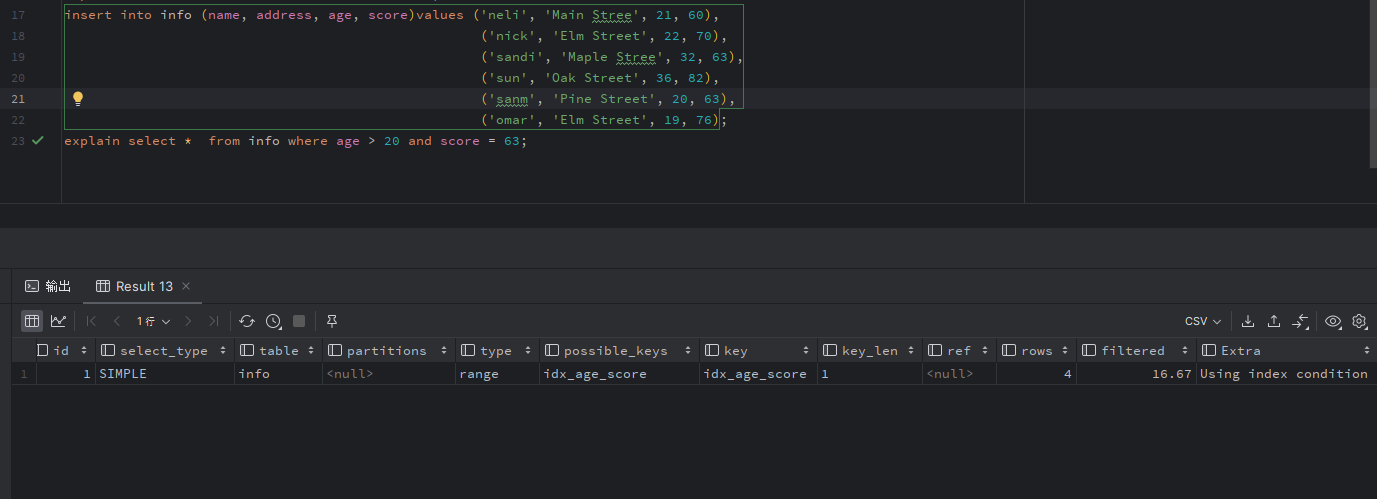
c. 查询中条件字段刚好是一个索引组里的.(覆盖索引)select * from info where age > 20 and record =xxx;
3. 执行器
经过优化器优化后接下来就是调用引擎接口指向SQL操作了,还是以上面的优化器例子为例,看看上面的语句都做了什么:
a.主键索引查询 select * from info where id=xxx;
- 执行器第一次查询会调用read_first_recode(),把查询调价传给引擎。
- 引擎定位到第一条符合查询条件的数据,将数据返给执行器
- 执行器判断记录是否符合查询条件,符合会发送给客户端(客户端接受到后会存起来等通知查询响应结束后再显示),不符合跳过
- 如果是唯一索引,引擎查询结束,否则调用read_recored(),接着上一条在循环中继续查询,重复上面的步骤,直到引擎报告查询完毕退出。这里查询类型 是const,表示索引唯一,所以不会继续查询。
b. 查询语句中没有索引可利用 - 全表扫描: select * from info where name=xxx; explain select *from info where name=xxx 查看执行计划:
因为info没有为name 建立二级索引。这是后优化器只能选择全表扫描全表扫描步骤和上面步骤基本一样,不易样的地方是:
- 首次查询仍调用read_first_record() , 引擎会把表的第一条数据返回个执行器;
- 其他和上面提到的步骤相同...
c. 查询中条件字段刚好是一个索引组里的 - 索引下推.(覆盖索引) select * from info where age > 20 and record =xxx;
这里限定条件MySQL 5.7 及以上,5.6 没有索引下推。MySQL 5.6下,引擎匹配到符合匹配条件里第一个条件的数据后会获取这条记录主键,根据主键回表读取完整数据行记录发给执行层,执行层再做剩余项匹配,符合发给客户端,否则跳过。
如何查看是否使用索引下推:explain 表Extra 列: using index condition, 表示使用索引下推,type 类 range 表示区间遍历(联合索引再遇到有带区间的查询条件时停止匹配。)
- 同上,定位到第一条满足查询条件里第一个条件的数据行。、
- 【索引下推】先不拿主键回表,判断下一个索引的的值是否满足查询语句中下一个的匹配条件,满足回表,读完整记录发执行层,否则,跳过。
- 执行层再判断其他条件是否符合。
- 等待引擎告知执行完毕。
Step5 查询结束,根据配置回收资源
- 根据配置文件配置的最大连接值max_connections 和连接最长空闲时间wait_timeout,是否开启长连接关键字决定连接资源的回收
一条写语句如何执行的?
前面说的是一条查询语句如何执行,这里说的是一条update语句如何执行...
下面提到的概念在这里可以找到 MySQL学习日记 -- 日志|ZklMao-Space
update t_test set name = "asan" where id = 123;
执行一条写语句大致分8步
- 优化器指定执行计划,选定执行计划
- 执行器获取计划,调用引擎接口,通过给定索引搜索 id = 123 的数据项:
- 如果 这条记录在buffer pool 中,返沪给执行器更新
- 不在buffer Pool 中从磁盘载入,返回给执行器更新
- 执行器拿到索引记录后,比较记录中的待更新项和新数据项:
- 相同不更新,不进行后续流程,直接返回
- 不相同,把当前记录和更新的记录当作参数传给innoDB,让引擎层真正更新记录
- 开启事务,记录undolog,生成一条相反的回滚更新语句,在redolog 加入对应undolog 变动记录。
- InnoDB 开始更新记录,先更新buffer pool 数据页中的数据项,并将对应页标记为脏页,将对应数据页变动记录记入redolog。 -- 这就是WAL 技术
- 记录binlog
- 事务提交,进入两阶段
- prepare : 将redolog 中对应事务状态记为 prepare. 随后刷盘
- commit :binlog 刷盘 调用引擎接口将事务状态 设置为commit
- done.

