
这篇讲的是SQL 优化技巧。内容大概如下:
explain 使用,如何分析一条SQL 查询是否走了索引?
索引优化示例
如何定位一条慢查询日志?
SQL 语句优化示例
深分页优化方案讨论
索引优化示例
MySQL 调优
MySQL 连接池 小技巧
explain 使用
这里主要介绍的是explain 几个主要关注的输出列对应关键词是什么意思,以及explain 的两个用法:
explain基本用法
explain SQL express : 在需要观察的SQL 语句前加 explain format=json xxx \G; 即可看到该语句的执行计划, \G 格式化数据, format=json 数据格式为json, json 格式输出执行计划会带有梅香计划的cost 执行成本。
show warnings :紧接上一次执行的explain,键入 show warnings 可获得额外信息,该信息可共开发者参考。
explain 输出项说明
这里以 MySQL 官网提供的 Sakila 电影制作公司样本数据库作为示例:
MySQL :: Sakila Sample Database :: 1 Preface and Legal Notices
下载地址: https://downloads.mysql.com/docs/sakila-db.zip
导入方法:
mysql -u 用户名 -p密码 数据库名 < 文件路径文件名.sql查看表结构
desc table_name;查看表索引
SHOW INDEX FROM your_table_name;查看库所有索引
SELECT TABLE_NAME, INDEX_NAME, COLUMN_NAME
FROM INFORMATION_SCHEMA.STATISTICS
WHERE TABLE_SCHEMA = 'your_database_name';表结构
CREATE TABLE actor (
actor_id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
first_name VARCHAR(45) NOT NULL,
last_name VARCHAR(45) NOT NULL,
last_update TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (actor_id),
KEY idx_actor_last_name (last_name)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
CREATE TABLE city (
city_id SMALLINT UNSIGNED NOT NULL AUTO_INCREMENT,
city VARCHAR(50) NOT NULL,
country_id SMALLINT UNSIGNED NOT NULL,
last_update TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (city_id),
KEY idx_fk_country_id (country_id),
CONSTRAINT `fk_city_country` FOREIGN KEY (country_id) REFERENCES country (country_id) ON DELETE RESTRICT ON UPDATE CASCADE
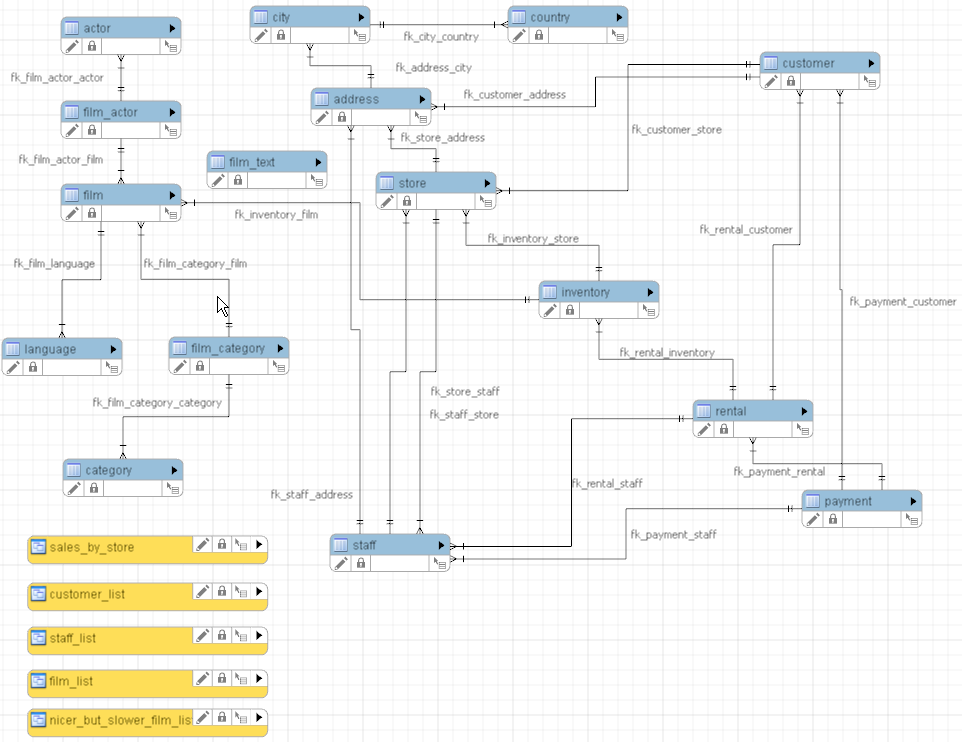
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;数据库ER图:
示例
mysql> explain select city, country_id from city where country_id > 55 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: city
partitions: NULL
type: ALL
possible_keys: idx_fk_country_id
key: NULL
key_len: NULL
ref: NULL
rows: 600
filtered: 47.67
Extra: Using where
1 row in set, 1 warning (0.00 sec)
ERROR:
No query specified
type: 访问数据表的方法
system : 访问的是引擎自带的数据,非常精准。比如MyISAM count(*) 返回的就是引擎维护的counter;
const: 通过有唯一约束的索引访问的数据。意味着匹配到合适数据马上停止,不会项普通索引那样扫描整个索引
ref : 普通二级索引查询
eq_ref // 表连接
range : 区间查询,比如使用in(...): where keyword=values in(values1,values2, ...)
index: 覆盖索引
index_merge: 索引合并,查询中发现条件列来自几个索引,这几个索引可以分别查找后(通过笛卡尔集合运算)合并数据返回。
all: 全表扫描
key: 访问表中数据使用的索引
possible_keys: 本次计划可能会使用到的索引
extra: 额外信息,这个很有用
impossible where : where 条件永远不成立。
using index: 索引覆盖
using index condition: 索引下推
using where : 全表扫描,使用SQL 语句中的where 条件 匹配数据
using join buffer(block nested loop):连接表查询不能通过索引有效匹配数据,就会用到临时内存做匹配数据。
using temporary: 使用了临时表
using filesort: 使用了临时文件去辅助排序,很有可能会将存有临时数据辅助文件存在磁盘里.
key_len: 本次访问的索引长度,索引半失效可可通过观查此项。比如联合索引由 (char(100) , INT)len = 100 + 4, explan key_len 输出项若小于 104 则说明索引部分失效,出现场景:索引覆盖-> 最左匹配生词效,但因后半部分条件语句中由 首字模糊查询、范围查询、反向查询等操作导致的失效... 具体失效哪一个可以观察key_len, 补数哪一个keylen 就是哪一个key失效。
row: 预计要扫描行数
filtered: 预计要在数据结果在row 中的占比.
如何分析一条SQL 查询是否走了索引?
Example 1 范围查询-索引失效
mysql> explain select city, country_id from city where country_id > 55 \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: city
partitions: NULL
type: ALL
possible_keys: idx_fk_country_id
key: NULL
key_len: NULL
ref: NULL
rows: 600
filtered: 47.67
Extra: Using where
1 row in set, 1 warning (0.00 sec)
ERROR:
No query specified
从表中 key: NULL 可以看出本次查询没有使用索引.
从 Extra: using where 可以看出扫描方式是全表扫描同过,where 条件来匹配数据.
Example 2 索引下推
mysql> explain select city, country_id from city where country_id in (55,31) \G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: city
partitions: NULL
type: range
possible_keys: idx_fk_country_id
key: idx_fk_country_id
key_len: 2
ref: NULL
rows: 2
filtered: 100.00
Extra: Using index condition
1 row in set, 1 warning (0.01 sec)
ERROR:
No query specified从 type: range 区间查找(区间匹配) where xxx in(...)
从 key: 可以看出本次查询使用索引 idx_fk_country_id.
从 key_len: 2 可以看出使用的索引列字段长度 len(SMALLINT) = 2
从 Extra: Using index condition 可以看出数据匹配使用了索引下推.
fows: 2 预计需要扫描的数据行数 2 行
filtered: 100.00 匹配记录数/本次扫描总行数 = 100.00%
SQL优化示例
本次使用的索引优化数据库样本仍然上面的样本。
Example 1 只取需要的列 节省内存
# 查寻 store_id = 62 的 customer 名称
select * from customer where store_id = 62;
-->
select first_name, last_name from city where store_id = 62;select* 会使 查询器将查询列扩展为所有列,存在无用大列的话会浪费内存空间。
Example 2 巧用 limit 只去取需求数据量的记录量 节省内存
explain (select first_name, last_name from sakila.actor order by last_name) union all (select first_name, last_name from sakila.customer order by last_name) limit 20;

explain format=json (select first_name, last_name from sakila.actor order by last_name) union all (select first_name, last_name from sakila.customer order by last_name) limit 20 \G;
*************************** 1. row ***************************
EXPLAIN: {
"query_block": {
"union_result": {
"using_temporary_table": false,
"query_specifications": [
{
"dependent": false,
"cacheable": true,
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "20.25"
},
"table": {
"table_name": "actor",
"access_type": "ALL",
"rows_examined_per_scan": 200,
"rows_produced_per_join": 200,
"filtered": "100.00",
"cost_info": {
"read_cost": "0.25",
"eval_cost": "20.00",
"prefix_cost": "20.25",
"data_read_per_join": "73K"
},
"used_columns": [
"first_name",
"last_name"
]
}
}
},
{
"dependent": false,
"cacheable": true,
"query_block": {
"select_id": 2,
"cost_info": {
"query_cost": "61.15"
},
"table": {
"table_name": "customer",
"access_type": "ALL",
"rows_examined_per_scan": 599,
"rows_produced_per_join": 599,
"filtered": "100.00",
"cost_info": {
"read_cost": "1.25",
"eval_cost": "59.90",
"prefix_cost": "61.15",
"data_read_per_join": "341K"
},
"used_columns": [
"first_name",
"last_name"
]
}
}
}
]
}
}
}
1 row in set, 1 warning (0.01 sec)
ERROR:
No query specified
优化后
explain (select first_name, last_name from sakila.actor order by last_name limit 20) union all (select first_name, last_name from sakila.customer order by last_name limit 20) limit 20;
mysql> explain format=json (select first_name, last_name from sakila.actor order by last_name limit 20) union all (select first_name, last_name from sakila.customer order by last_name limit 20) limit 20 \G;
*************************** 1. row ***************************
EXPLAIN: {
"query_block": {
"union_result": {
"using_temporary_table": false,
"query_specifications": [
{
"dependent": false,
"cacheable": true,
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "20.25"
},
"ordering_operation": {
"using_filesort": true,
"table": {
"table_name": "actor",
"access_type": "ALL",
"rows_examined_per_scan": 200,
"rows_produced_per_join": 200,
"filtered": "100.00",
"cost_info": {
"read_cost": "0.25",
"eval_cost": "20.00",
"prefix_cost": "20.25",
"data_read_per_join": "73K"
},
"used_columns": [
"actor_id",
"first_name",
"last_name"
]
}
}
}
},
{
"dependent": false,
"cacheable": true,
"query_block": {
"select_id": 2,
"cost_info": {
"query_cost": "61.15"
},
"ordering_operation": {
"using_filesort": true,
"table": {
"table_name": "customer",
"access_type": "ALL",
"rows_examined_per_scan": 599,
"rows_produced_per_join": 599,
"filtered": "100.00",
"cost_info": {
"read_cost": "1.25",
"eval_cost": "59.90",
"prefix_cost": "61.15",
"data_read_per_join": "341K"
},
"used_columns": [
"customer_id",
"first_name",
"last_name"
]
}
}
}
}
]
}
}
}
1 row in set, 1 warning (0.00 sec)
ERROR:
No query specifiedOS: 这么写可以减少数据扫描项(《高性能 mysql 第四版》P290)
语句一会取扫描sakila.actor 全表 200条记录和 sakila.customer 599 条记录。扫描完后再对这些记录做连接,返回几乎给上层
语句一会取扫描sakila.actor 只取 20条记录和 sakila.customer 只取 20 条记录。扫描完后再对这些记录做连接,返回几乎给上层
优化的点在于内存上的节省... 但是实验并未看出来....得抽时间复现环境...
Example 3 表连接,以小驱大,减少IO
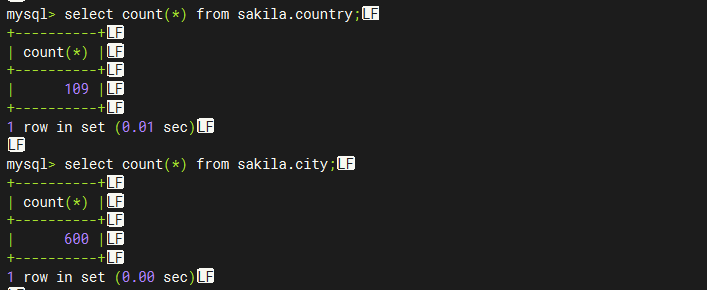
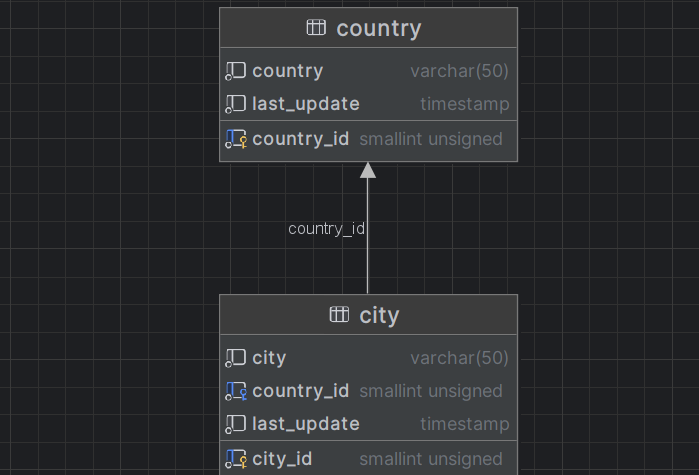
city --> country
select sakila.country.country, sakila.country.country_id, sakila.city.city, sakila.city.city_id from sakila.city join sakila.country where sakila.country.country_id = sakila.city.country_id;优化后:
country --> city
explain select sakila.country.country, sakila.country.country_id, sakila.city.city, sakila.city.city_id from sakila.country join sakila.city where sakila.country.country_id = sakila.city.country_id;OS1:左连接左右表可以互换,MySQL 优化器会根据每个表的引擎统计信息 调换表连接顺序。
OS2: 右连接可以改写成左连接,套娃上面的OS 优化....
Example 4 以小驱大,子查询放大表,主查询尽可能小,主 --> 子
把大表方子查询,小表方主查询,开启半连接优化...
explain select sakila.city.country_id from sakila.city where sakila.city.country_id in (select sakila.country.country_id from sakila.country);
优化后 ---->
explain select sakila.country.country_id from sakila.country where sakila.country.country_id in (select sakila.city.country_id from sakila.city);
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "98.46"
},
"nested_loop": [
{
"table": {
"table_name": "country",
"access_type": "index",
"possible_keys": [
"PRIMARY"
],
"key": "PRIMARY",
"used_key_parts": [
"country_id"
],
"key_length": "2",
"rows_examined_per_scan": 109,
"rows_produced_per_join": 109,
"filtered": "100.00",
"using_index": true,
"cost_info": {
"read_cost": "0.25",
"eval_cost": "10.90",
"prefix_cost": "11.15",
"data_read_per_join": "22K"
},
"used_columns": [
"country_id"
]
}
},
{
"table": {
"table_name": "city",
"access_type": "ref",
"possible_keys": [
"idx_fk_country_id"
],
"key": "idx_fk_country_id",
"used_key_parts": [
"country_id"
],
"key_length": "2",
"ref": [
"sakila.country.country_id"
],
"rows_examined_per_scan": 5, # 5
"rows_produced_per_join": 600, # ----------- 600 注意这里的连接行 ---> 5 * 600
"filtered": "100.00",
"using_index": true,
"cost_info": {
"read_cost": "27.31",
"eval_cost": "60.00",
"prefix_cost": "98.46",
"data_read_per_join": "126K"
},
"used_columns": [
"country_id"
]
}
}
]
}
}
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "98.46"
},
"nested_loop": [
{
"table": {
"table_name": "country",
"access_type": "index",
"possible_keys": [
"PRIMARY"
],
"key": "PRIMARY",
"used_key_parts": [
"country_id"
],
"key_length": "2",
"rows_examined_per_scan": 109,
"rows_produced_per_join": 109,
"filtered": "100.00",
"using_index": true,
"cost_info": {
"read_cost": "0.25",
"eval_cost": "10.90",
"prefix_cost": "11.15",
"data_read_per_join": "22K"
},
"used_columns": [
"country_id"
]
}
},
{
"table": {
"table_name": "city",
"access_type": "ref",
"possible_keys": [
"idx_fk_country_id"
],
"key": "idx_fk_country_id",
"used_key_parts": [
"country_id"
],
"key_length": "2",
"ref": [
"sakila.country.country_id"
],
"rows_examined_per_scan": 5, #
"rows_produced_per_join": 109, # ----------- 600 -> 109 优化up! ---> 5 * 109
"filtered": "100.00",
"using_index": true,
"first_match": "country",
"cost_info": {
"read_cost": "27.31",
"eval_cost": "10.90",
"prefix_cost": "98.46",
"data_read_per_join": "22K"
},
"used_columns": [
"country_id"
]
}
}
]
}
}注意观察上面的成本日志,从5*600 笛卡尔连接 ,使用以小驱大后,优化成 5*109 -- 因为开启了半连接优化
Example 5 以小驱大 In(...) 后置
优化规则同上 Example 4
select xxx, xxx, xxx from table where colum in(sql) and id = 10;
--- 优化后 -->
select xxx, xxx, xxx from table where id = 10 and colum in(sql);深分页优化方案讨论
深分页问题是指 limit offset 参数大,导致扫描记录过多,占用内存过多导致查询过慢的问题。全表扫描的原因是 innodb 官方未实现索引下推。以下是可行的优化方案
改写SQL,如果数据有序,可以改写 为 where key >= 区间起始,limit 需求记录行数,这样就可以走索引加速查询。
Example :
select uid,name,age from user limit 1000 10; # uid 有序 假设1000 偏移1000 后的第一条数据uid=1000
那么有 1000 的后10条 id = 1001 ....
此时可以改写为 where
select uid,name,age from user where id > 1000 limit 10;
使用厂商优化版本,比如阿里云、腾讯的优化过的MySQL 就支持深分页索引下推。
从实际业务出发,分页加载,比如查询1000行后的后10行,可以将1000分成20页,每页查询50行,分成20页显示等用户触发翻页时再去查下一个50行,减少扫描量降低内存使用,最后,显示深分页参数值不能过大,从源头拒绝深分页。上面这个策略很常见,在搜索引擎中,比如百度最大分页只有76页。
索引优化示例
where a > 1 and b = 2 and c < 3 该怎么建立索引
表结构
mysql> desc actor;
+-------+-------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------------+------+-----+---------+----------------+
| a | smallint unsigned | NO | | NULL | auto_increment |
| b | smallint unsigned | NO | | NULL | |
| c | smallint unsigned | NO | | NULL | |
+-------+-------------------+------+-----+---------+----------------+原始查询计划
mysql> explain select a,b,c from actor where a > 1 and b = 2 and c < 6;
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | actor | NULL | range | PRIMARY | PRIMARY | 2 | NULL | 12 | 7.69 | Using where |
+----+-------------+-------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.01 sec)别急看答案,先看最左匹配原理
假设我们现在为上面的表建立索引 index_abc(a,b,c), actor 表有如下数据

那个建立起来的B+ 数索引大概是这样的(画的不是实际innodb 存储的样子,只是示意图,别喷)
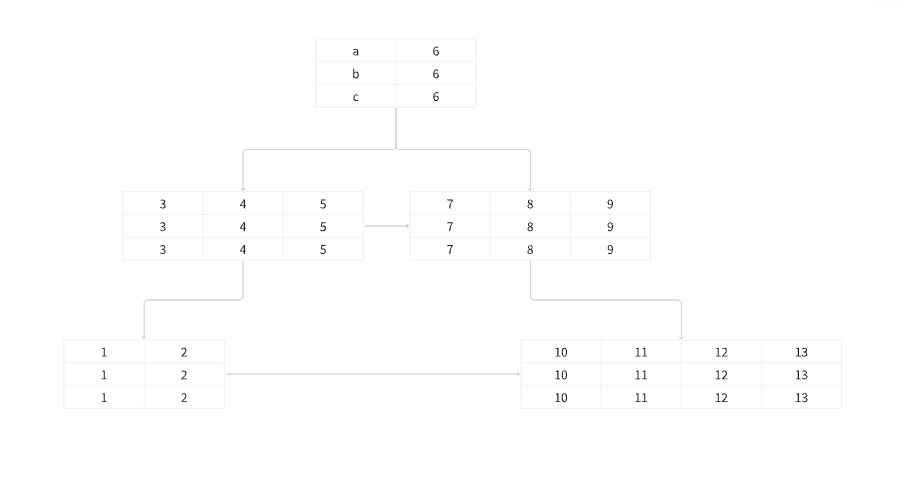
innoDB 会以定义索引的首列作为B+树的master key(就是用来做查找时匹配的key,有点像红黑树中的key), 之后按定义数据去存储剩余列的数据...
别急看答案,再看最左匹配规则
最左匹配规则:
8.0 之前,查询中一定要出现最左索引列(出现顺序任意),否则索引失效,8.0 后没写最左列会自动加入,且出现的最左列一定会被使用去查询,生效再去做匹配
如果查询条件中有范围查询(或是模糊查询),那个范围查询之后的索引列失配(失效)
那么问题来了怎么建立索引才能使查询更高效?
ALTER TABLE actor ADD INDEX index_bac (a,b,c); or ALTER TABLE actor ADD INDEX index_bac (a,c,b); ... # 1
ALTER TABLE actor ADD INDEX index_bac (b,a,c); # 2根据最左匹配原则:
如果把范围查询的a或c 放最左列,那么会a,c就会被最先使用去匹配查询,又因为a、c 是范围查询,所以范围查询之后的索引列会全部失效。
所以如果要把覆盖索引最大化利用,就应该把非范围查询的列放到最前面,也就是采用方案二,让等值查询先上
验证:
添加索引
ALTER TABLE actor ADD INDEX index_bac (b,a,c);
ALTER TABLE actor ADD INDEX index_bac (a,b,c);
ALTER TABLE actor ADD INDEX index_bac (a,c,b);查询计划 #1 (添加 #1 索引后,此时# 2 未添加,否则会选择#2)

查询计划 #2

可以看到 #2 比 #1 占比 33.33 > 7.69,key_len 4 > 2, 优化有效!
其他SQL 优化小技巧
连表查询尽量不要关联太多表
不要使用like 左模糊查询和全模糊查询,会导致索引失效
尽量不要对字段做 is null、not is null 判断,会导致索引失效,因为区分度不大
不要在条件查询=前对字段做任何运算,不要让字段参与运算,因为索引是对字段值的索引,不是对函数的索引,如果要对函数的值索引,请使用函数索引
!=、!<>、not in、no like、or 慎用,or 可以用 uion all 替代
必要情况下可以强制指定 索引 select xxx from table_name force index(index_name) ...;
避免频繁创建、销毁临时表
尽量拆分大事务为小事务,因为小事务的数据可能耦合对不会有大事务那么耦合,原子性更强可以复用。
尽量避免深分页,因为MySQL 官方引擎 innodb 不会做索引下推. 如 select xxx from yyy limit 10000,10; 取10000行数据后的 10行记录,innoDB 不会直接定位到10000行后开始扫描,而是从第一条开始扫描,扫描到10000+10 后停止,抛弃前10000条后返回目标数据。其他厂商的可能会提供这一优化.
SQL 列名写完整,select tablename.colum_name1,tablename.colum_name2 ... from xxx where tablename.colum_name1 = tablename.colum_name2; 因为MySQL 后面重写SQL语句的时候会自己加上,会多做一步...
明确仅返回一条数据时请使用 limit 1;
MySQL 调优小技巧
配置文件名 my.ini/my.conf
设置buffer pool 大小 innodb_buffer_pool_size
性能优化步骤
监控,发现瓶颈
排查瓶颈原因
定位瓶颈位置
解决性能瓶颈
连接池小技巧
MySQL 线程池常驻线程参考公式 core * 1 + 有效磁盘数(SSD)
MySQL 线程池最大线程 core *2 + 有效磁盘数 (PostgreSQL 官方建议)

