
这里主要是用示意图的方式去介绍Go 几个常见类型结构:
string
slice
map
sync.map
channel
context
defer
interface
String
string 源码中的定义
type stringStruct struct {
str unsafe.Pointer // data
len int // len
}示意图见下:

特性:
go string 不和C++中的 std::string 一样 支持按rank 修改 [_n] = 'x', 只支持对象之间的等值赋值,若需按rank 赋值,需转换为 slice 再做 按rank 赋值
string <-------------- = ---------------> slice 朴素按值拷贝,没有任何优化
slice ---> string
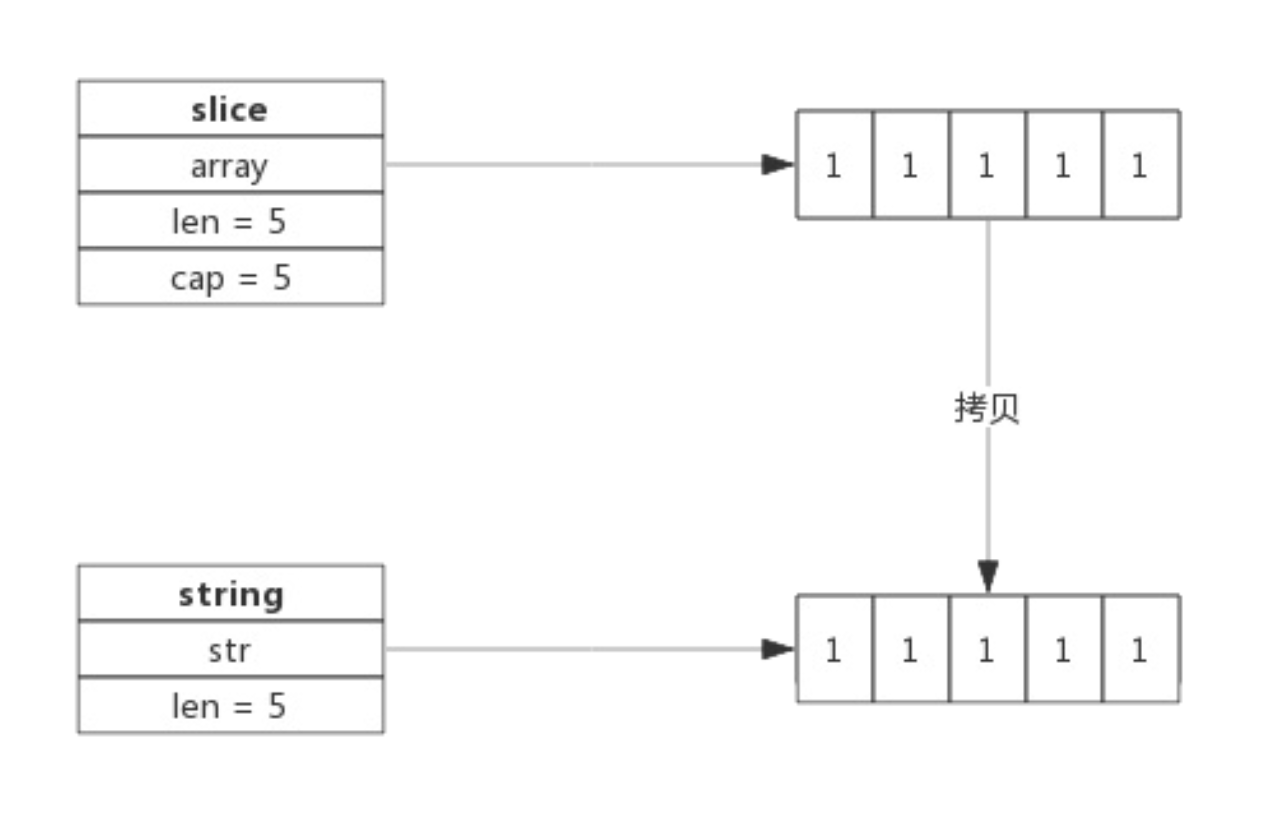
string ----> slice
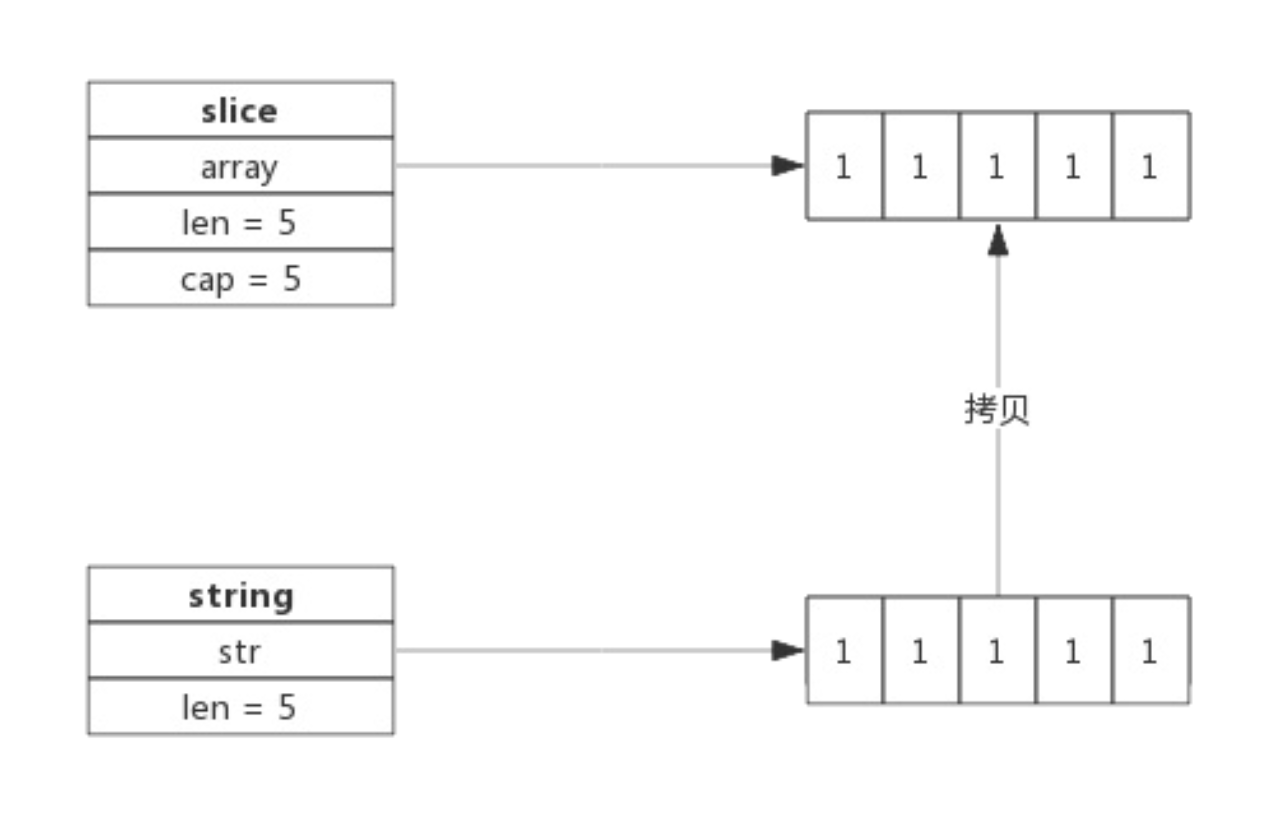
slice
slice 源码定义
//go 1.20.3 path: /src/runtime/slice.go
type slice struct {
array unsafe.Pointer // data
len int // used len
cap int // Pre allocated capacity
}示意图见下:
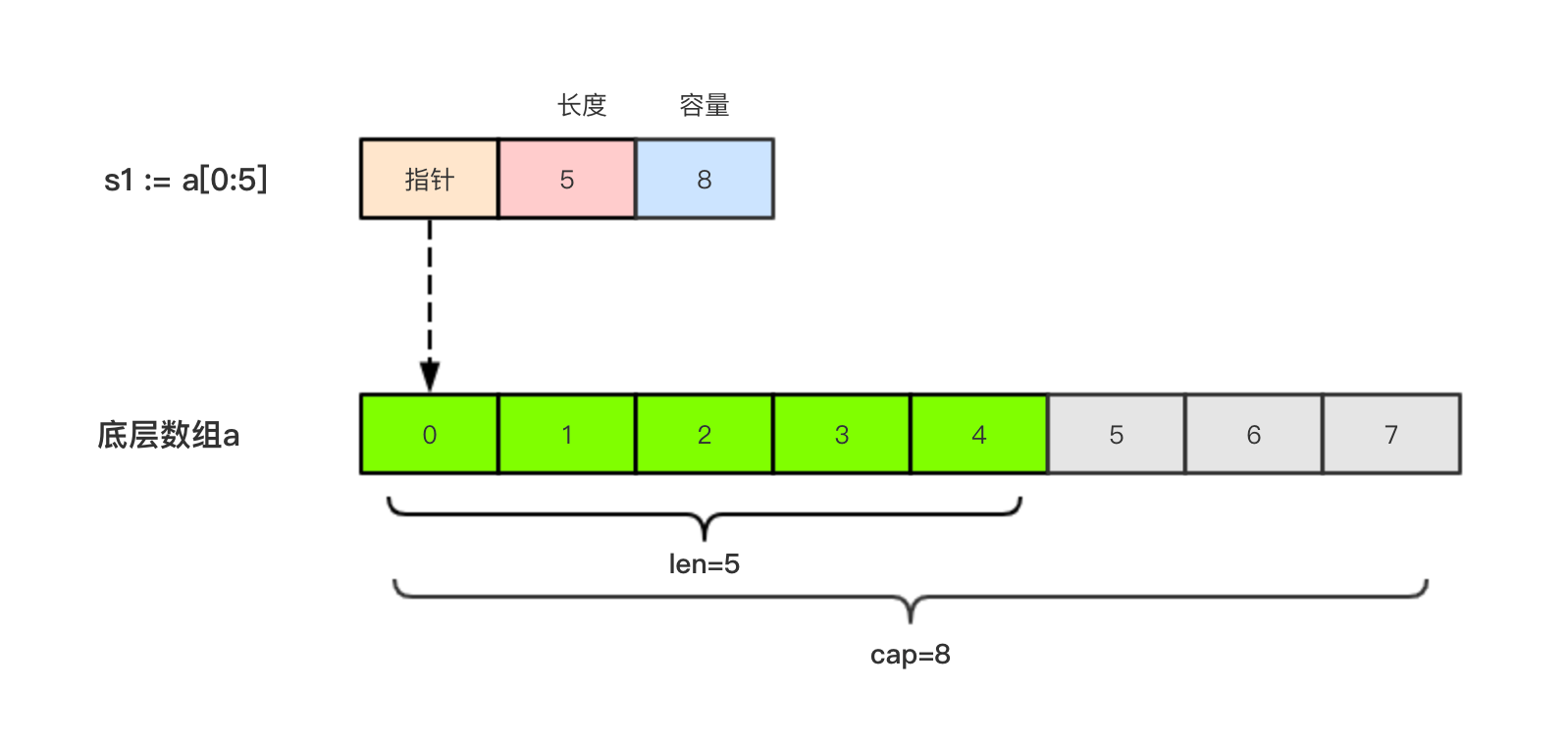
特性:
支持动态扩容
扩容机制示意图:

对应源码:
//go 1.20.3 path: /src/runtime/slice.go
func growslice(oldPtr unsafe.Pointer, newLen, oldCap, num int, et *_type) slice {
// 计算旧切片的长度,等于新切片的长度减去要添加的元素个数
oldLen := newLen - num
......
// 如果新切片的长度为负数,说明溢出了,直接panic
if newLen < 0 {
panic(errorString("growslice: len out of range"))
}
//如果元素类型的大小为0,说明是空切片,直接返回一个新的切片
if et.size == 0 {
return slice{unsafe.Pointer(&zerobase), newLen, newLen}
}
// 定义一个新的切片容量newcap,初始值为旧切片的容量
newcap := oldCap
//定义一个新的切片doublecap,初始值为旧切片容量的两倍
doublecap := newcap + newcap
if newLen > doublecap {
//如果新切片长度大于doublecap(旧切片容量的两倍),则新切片容量为新切片长度
newcap = newLen
} else {
//否则,定义一个常量threshold,等于256
const threshold = 256
if oldCap < threshold {
//如果旧切片容量小于256,则新切片容量为(doublecap)旧切片容量的两倍
newcap = doublecap
} else {
//循环增加新切片容量,直到大于或者等于新切片长度或者溢出
for 0 < newcap && newcap < newLen {
//每次增加新切片容量的四分之一
newcap += (newcap + 3*threshold) / 4
}
//如果新切片容量小于等于0,则新切片容量等于新切片长度
if newcap <= 0 {
newcap = newLen
}
}
}
......
}
Go语言基础结构 —— Slice 切片_go slice-CSDN博客
Golang语言之切片(slice)快速入门篇 - 尹正杰 - 博客园
cow 优化
切片之间赋值(包括切片部分赋值,tip: a = b[2:] ),仅将数据指针指向同内存地址,修改时才会拷贝一个副本再做修改
所有切片之间的拷贝都是浅拷贝。若需做深拷贝,请用 copy 函数 tip : copy(s1,s2)
切片扩容后很有可能存储数据得内存不是原内存,若需使用同一内存地址,请用 : str.appen(str,'data')
切片申请得内存容量会做内存对齐
与数组区别:
数组声明时会显式声明数组长度,无预分配空间,不支持动态扩容,但数组和切片可以互转
有了数组,为什么要设计切片?
数组是固定的,无法应对动态长度,之所以拆分是为了职责单一
切片按值函数传参,传得是什么?
会做传入值的浅拷贝
map
map 源码定义
type hmap struct {
count int // 键值对总数,可以使用 len() 内置函数来获取
flags uint8 // 标识位,用于记录和管理map的状态,比如是否被并发读写
B uint8 // 计算哈希桶数值的,哈希桶数量为2的B次方
noverflow uint16 // 溢出桶数量
hash0 uint32 // 哈希种子
buckets unsafe.Pointer // 是一个指向 Bucket 数组的指针 实际存储数据的地方
oldbuckets unsafe.Pointer // 扩容时,保存旧的桶数组的指针
nevacuate uintptr // 扩容时的进度标识。小于这个值的桶已经完成了迁移
extra *mapextra // 指向 mapextra 结构体的指针
}
type mapextra struct {
overflow *[]*bmap // 包含了 hmap.buckets 的溢出桶
oldoverflow *[]*bmap //包含了 hmap.oldbuckets 的溢出桶
nextOverflow *bmap // 下一个可用的溢出桶
}
const bucketCnt = 8
// bmap 就是 map 中的桶,可以存储 8 组 key-value 对的数据,以及一个指向下一个溢出桶的指针
type bmap struct {
tophash [bucketCnt]uint8
}
// 上面的 bmap 只是表面(runtime/map.go)的结构,编译期间会动态地创建一个新的结构
// 每组 key-value 对数据包含 key 高 8 位 hash 值 tophash,key 和 value
type bmap struct {
tophash [bucketCnt]uint8
keys [bucketCnt]keytype
values [bucketCnt]valuetype
pad uintptr
overflow uintptr
}示意图如下:
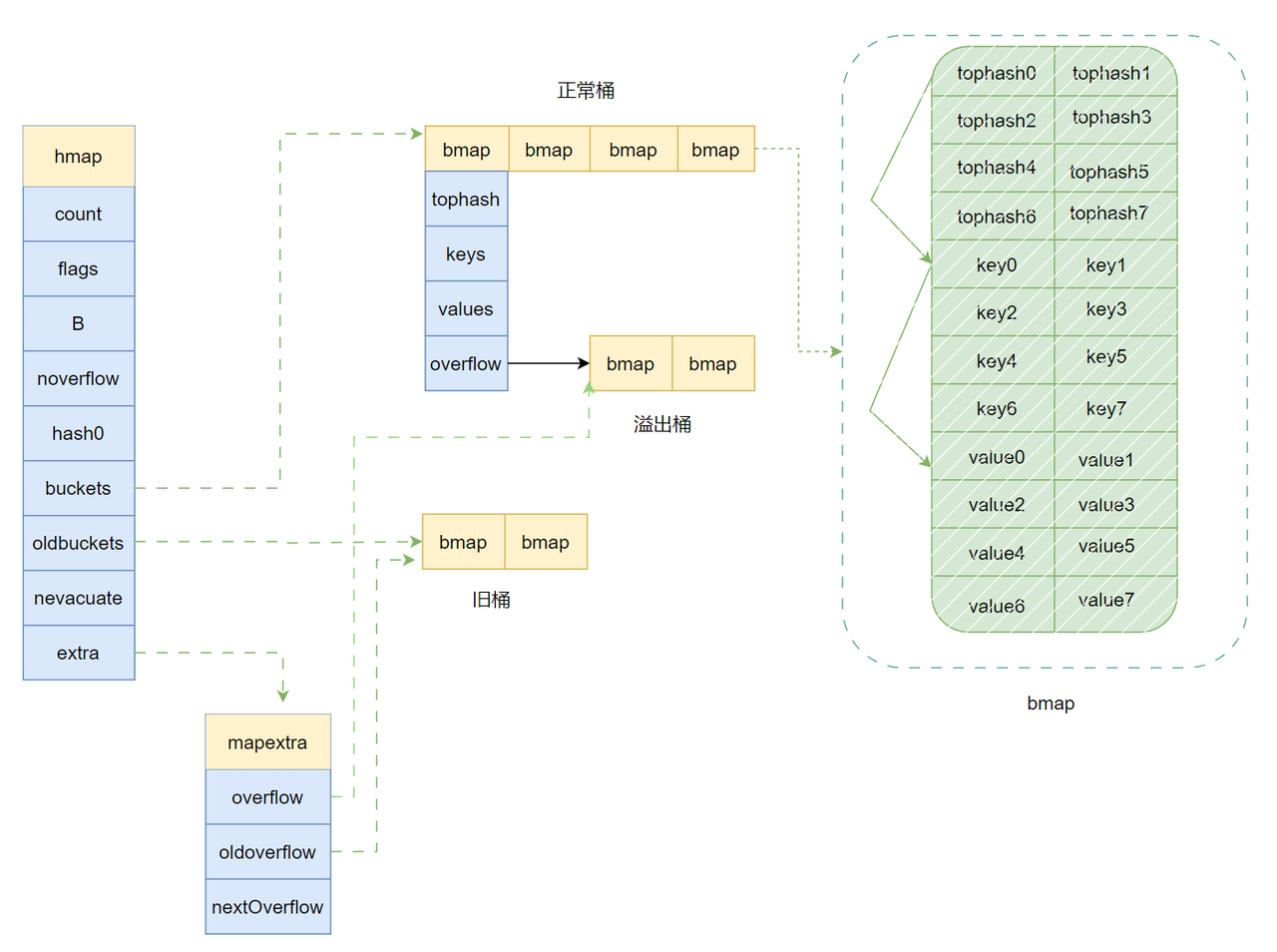
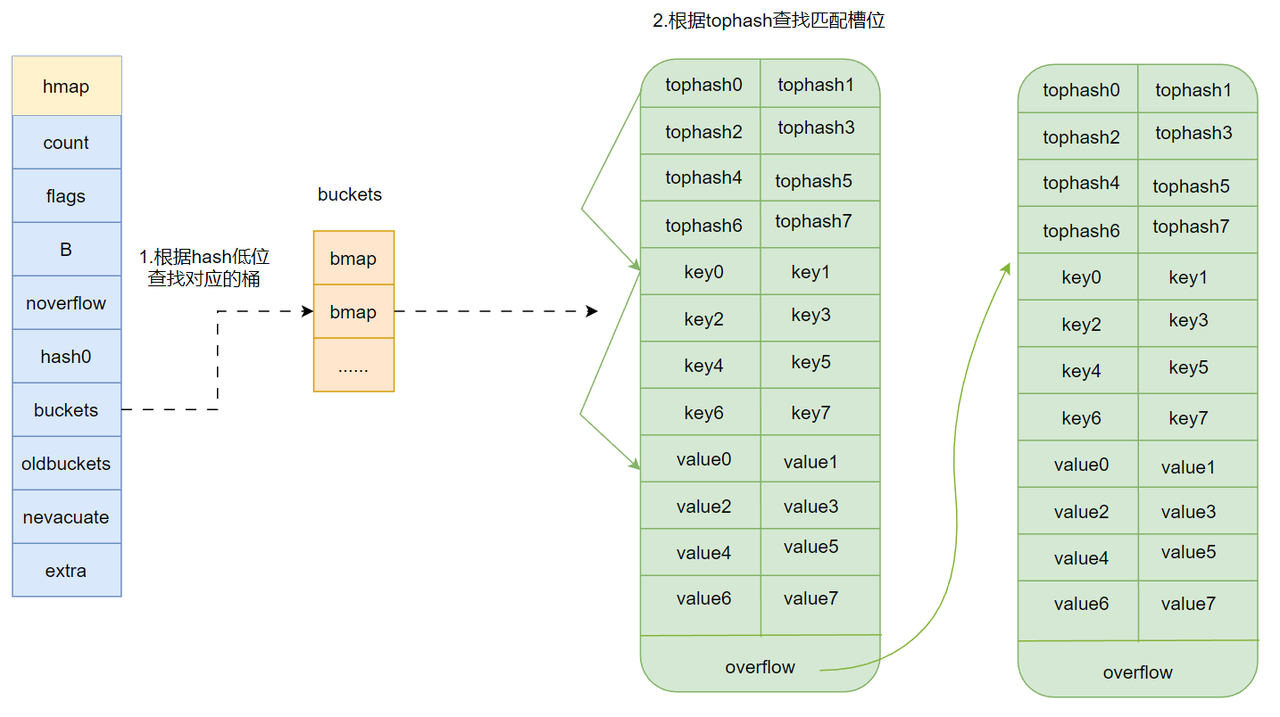
特性:
不支持并发读写, 并发读写会报错(实现原理时再hmap 中有一个写标志标志位),设计之初就确定了map 的应用场景,map 用于并发多读场景。若想使用支持并发读写的map请使用 sync.map.
改进的拉链法,解决哈希冲突
数据遍历无序,因为map 库容后原数据很有可能会被迁移到新桶中与原map 中不同的位置。
采用惰性库容,增删改时触发库容检查,每迁移一个桶的数据,扩容进度计数器 + 1
扩容因子 6.5 = 82.5% (刚好到通用资源警戒值) --> 6.5 / 8 ,因为每个bmap 存8 个key-val, 6.5 刚好 大于 80%
sync.map
源码定义
// sync/map.go
type Map struct {
mu Mutex // 互斥锁,用于保护dirty字段和misses字段。
read atomic.Value // readOnly, 一个atomic.Value类型的字段,存储了一个readOnly结构体,用于存储只读数据。
dirty map[interface{}]*entry // 一个map,存储了所有可写的键值对。
misses int // 一个计数器,记录了从read读取失败的次数,用于触发将数据从dirty迁移到read的决策。
}
type readOnly struct {
m map[interface{}]*entry // 实际存储键值对的map。
amended bool // 标记位,如果dirty中有read中没有的键,那么为true
}示意图如下:
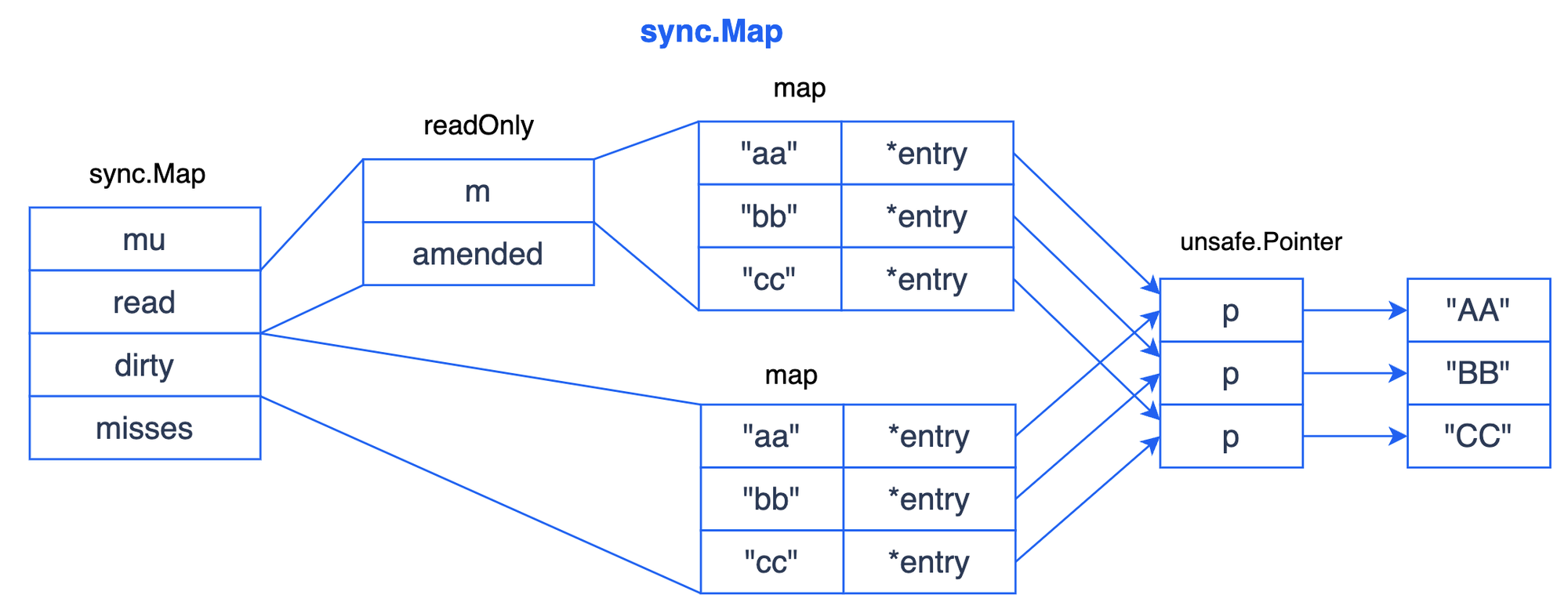
深入理解Go语音的sync.Map-腾讯云开发者社区-腾讯云
特性:
空间换时间,读写分离保证并发性能, readonly map 读取数据是无锁读取,会做double check(第二次check 是否存在会加锁),查询不到,会查dirty map. dirty map 是 read map 的全量兜底数据
有缓存命中计数器,计数器大于等于某个阈值,就会做数据切换,将readonly map 替换成dirtymap(直接指针变量值的替换)。
存在性能抖动,如果数据量很大,发生数据切换时会加锁做重建dirty map. 时间复杂度 O(N) 此时整个sync.map 将会被加锁, 知道数据重建完成
适用于读多,更新多,删除少,插入少的场景
采用惰性删除,在对应key-val 块 entry 中标记位 nil 表示为软删除,实际在存在两map 中,在重建drity map 时会将所为标记有删除标记的kv entry 拷贝到dirty map 中,并将 nil 标记 修改为 unexguned 表示彻底删除(硬删除)
entry 声明周期
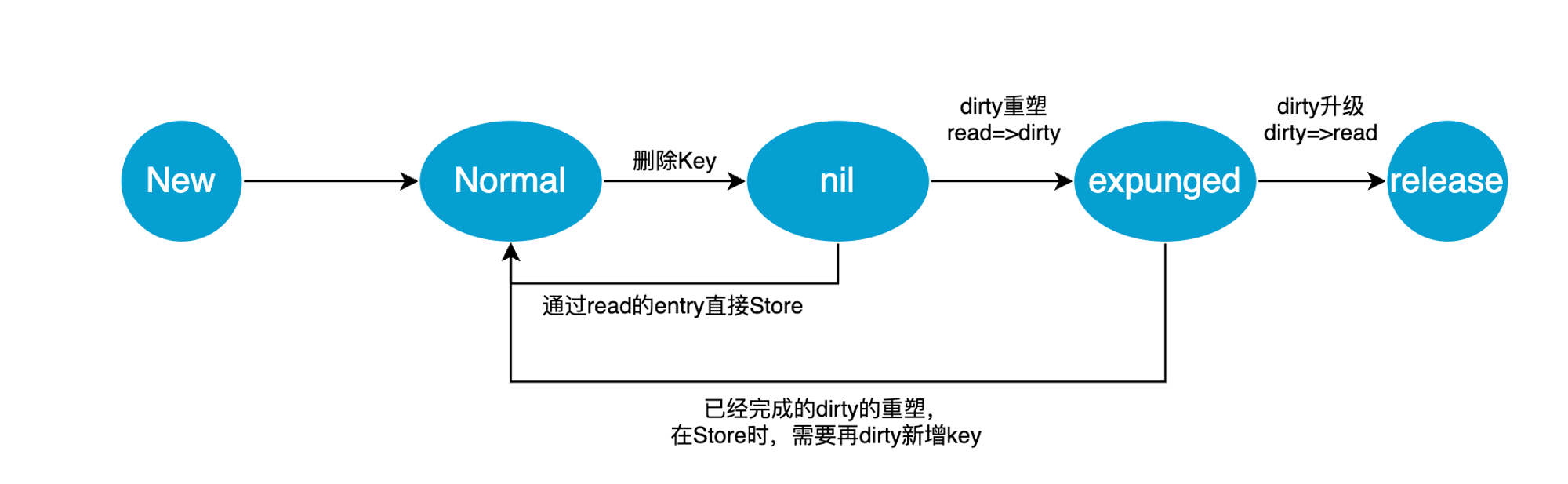
dirty 重建:为nil 有新数据写入的时候。
更新优先级,read only > dirty map。
channel
chanel 源码定义
type hchan struct {
qcount uint // channel 环形数组中元素的数量
dataqsiz uint // channel 环形数组的容量
buf unsafe.Pointer // 指向channel 环形数组的一个指针
elemsize uint16 // 元素所占的字节数
closed uint32 // 是否关闭
elemtype *_type // 元素类型
sendx uint // send index 下一次写的位置
recvx uint // receive index 下一次读的位置
recvq waitq // list of recv waiters 读等待队列
sendq waitq // list of send waiters 写等待队列
lock mutex // runtime.mutex,保证channel并发安全
}
type waitq struct {
first *sudog // sudog队列的队头指针
last *sudog // sudog队列的队尾指针
}
这段代码是Go语言的源码中的一部分,它定义了一个名为`sudog`的结构体,这个结构体是Go语言并发模型中用于调度goroutine在channel上进行通信操作的关键组件。
type sudog struct {
g *g // 绑定的goroutine
// 这里存储了一个指向goroutine的指针,这个goroutine正在等待channel上的某个操作。
next *sudog // 前后指针
prev *sudog
// 这两个字段形成了双向链表,用于管理等待同一个channel操作的所有goroutine。
elem unsafe.Pointer // 存储元素的容器
// 这个字段是一个指针,用于存储从channel接收的数据或者将要发送到channel的数据。
isSelect bool // 标识是不是因为select操作封装的sudog
// 这个布尔字段用于区分当前sudog是因为select语句中的多个channel操作之一而创建的。
success bool // 为true,表示这个sudog是因为channel通信唤醒的
// 这个布尔字段表示goroutine是因为channel上的通信操作(如发送或接收)而被唤醒的。
c *hchan // 绑定的channel
// 这个字段是一个指向hchan结构体的指针,hchan是Go语言中channel的内部表示。
}
每个等待channel操作的goroutine都会被封装在一个`sudog`结构体中,并被加入到对应channel的等待队列中。当channel上的某个操作可以进行时(比如,有数据可以接收或者缓冲区有空位可以发送数据),运行时会从等待队列中取出一个`sudog`,并唤醒对应的goroutine,让sudog 绑定的G 重新加入调度。示意图如下:
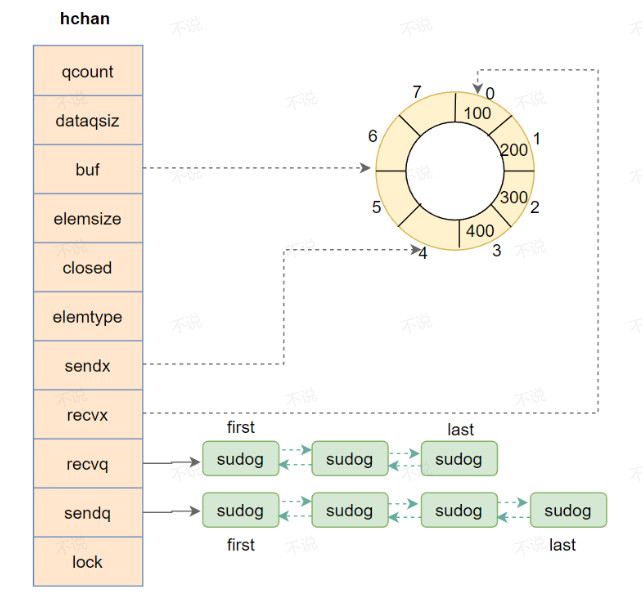
特性:
写一个已经关闭的 chan 会painc
关闭一个 chan 会painc
读一个 已将关闭的 chan 会返回0, 返回 false v, ok = <- c
读写一个 nil 为实例化的 chan 会永久阻塞挂起 当前goruntiune
chan 在堆上实例化
chan 值传送是 只拷贝,即协程之间通过chan 传递数据 是通过拷贝传递
chan 中的数据缓冲区是环形缓冲区,由读写位置指针控制
chan上读写协程 分别挂 读写协程链表队列上。
context
context 源码定义
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}
// A cancelCtx can be canceled. When canceled, it also cancels any children
// that implement canceler.
type cancelCtx struct {
Context
mu sync.Mutex // protects following fields
done atomic.Value // of chan struct{}, created lazily, closed by first cancel call
children map[canceler]struct{} // set to nil by the first cancel call
err error // set to non-nil by the first cancel call
}特性:
有四个类型: emptyCtx、cancelCtx、timerCtx、valueCtx
emptyCtx 一般用作根Ctx
cannelCtx 在退出时会不但会调用设置好的取消函数通知自身节点退出,还会通知下树子节点一起退出
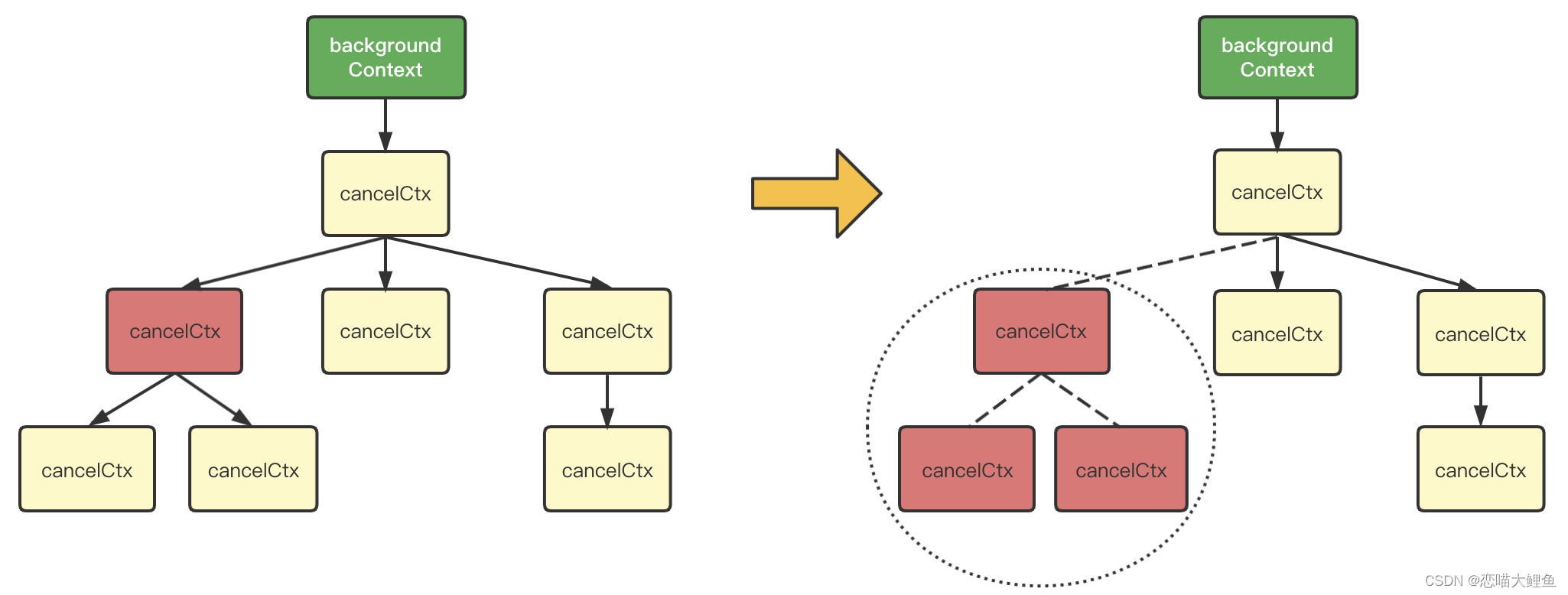
timerCtx 定时器的cancelCtx
valueCtx,可带KV信息的Ctx,常用于配置传递
Context 用来干什么?
goruntiune 之间传递上下文信息
批量管理有父子(线性)关系的 goruntiune 集群,防止goruntiue 泄露。
配置传递。
defer
defer 源码定义
type _defer struct {
started bool // 标志位,标识defer函数是否已经开始执行,默认为false
heap bool // 标记位,标志当前defer结构是否是分配在堆上
openDefer bool // 标记位,标识当前defer是否以开放编码的方式实现
sp uintptr // 调用方的sp寄存器指针,即栈指针
pc uintptr // 调用方的程序计数器指针
fn func() // defer注册的延迟执行的函数
_panic *_panic // 标识是否panic时触发,非panic触发时,为nil
link *_defer // defer链表
fd unsafe.Pointer // defer调用的相关参数
varp uintptr // value of varp for the stack frame
framepc uintptr // 函数调用的程序计数器值
}示意图见下:
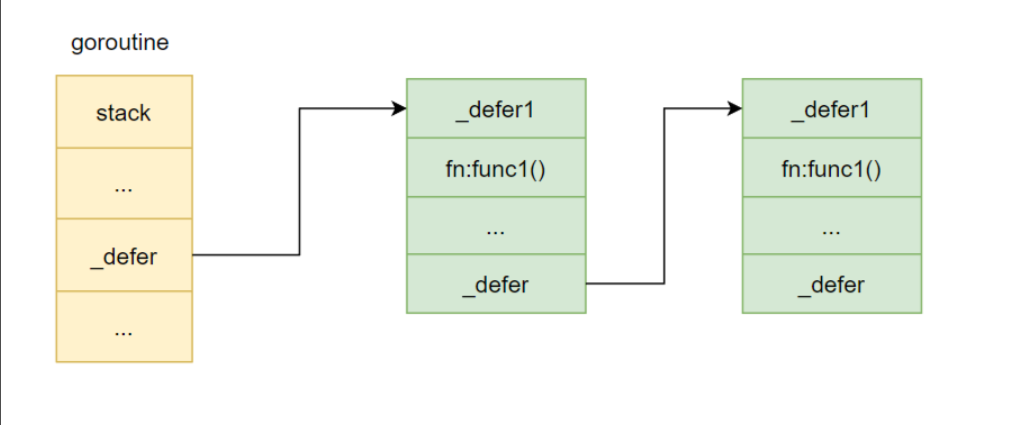
特性:
在SSA 阶段处理,界定defer 控制块在stack/heap/内联(inline) 上实例化
满足下面条件,defer 函数会做内联处理:
编译时没有设置 -N 参数
这个函数里 defer 函数没有超过 8个
defer 所在函数 返回值 x 参数 < 15 个
defer 没有出现在循环中
defer 可以修改函数返回值
所在函数进入返回阶段,回在绑定的协程中按顺序执行defer 链表中的defer 函数
defer 和 return 执行顺序?
设置返回值
执行defer
返回结果
多个defer 执行顺序?
类似栈机制,从上到下挂在到defer 链表中,先进后出。
循环中调用defer会有什么问题?
循环中调用defer 会影响程序性能,因为无法将defer 函数内联处理,也不能在栈上实例化defer 控制块,最终只能在堆中实例化
适用不当的化defer 的延迟执行特点回导致某些内核资源泄露,tip:
_,filename := range filelists {
fd, ok := os.Open(filename)
if ok != nil{
return err
}
defer fd.Close()
}
上面的 defer 不到该 循环的该协程的声明周期最后一刻时不会执行的。这就会导致句柄泄露。
interface
interface 源码定义
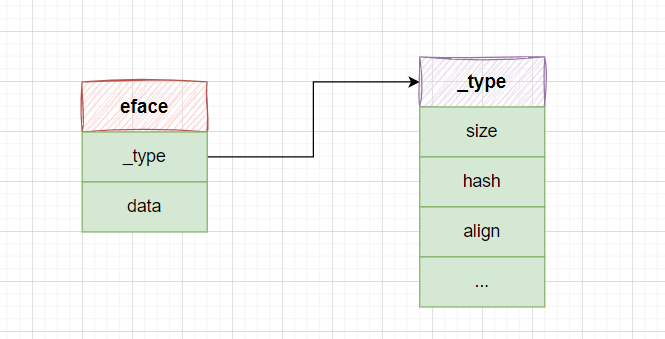
type eface struct {
_type *_type // CRT 信息指针
data unsafe.Pointer // 对象数据指针
}
type _type struct {
size uintptr // 数据类型占用的空间大小
ptrdata uintptr // 前缀持有所有指针的内存大小
hash uint32 // 类型的hash值
tflag tflag // 信息标志
align uint8 // 这种类型在内存中的对齐方式
fieldAlign uint8 // 字段对齐方式
kind uint8 // 类型编号
equal func(unsafe.Pointer, unsafe.Pointer) bool // 类型的比较函数
gcdata *byte // GC数据
str nameOff // 类型名称在字符串表中的位置
ptrToThis typeOff // 指向当前类型的指针的类型
}示意图如下:
Go-接口interface底层实现-腾讯云开发者社区-腾讯云
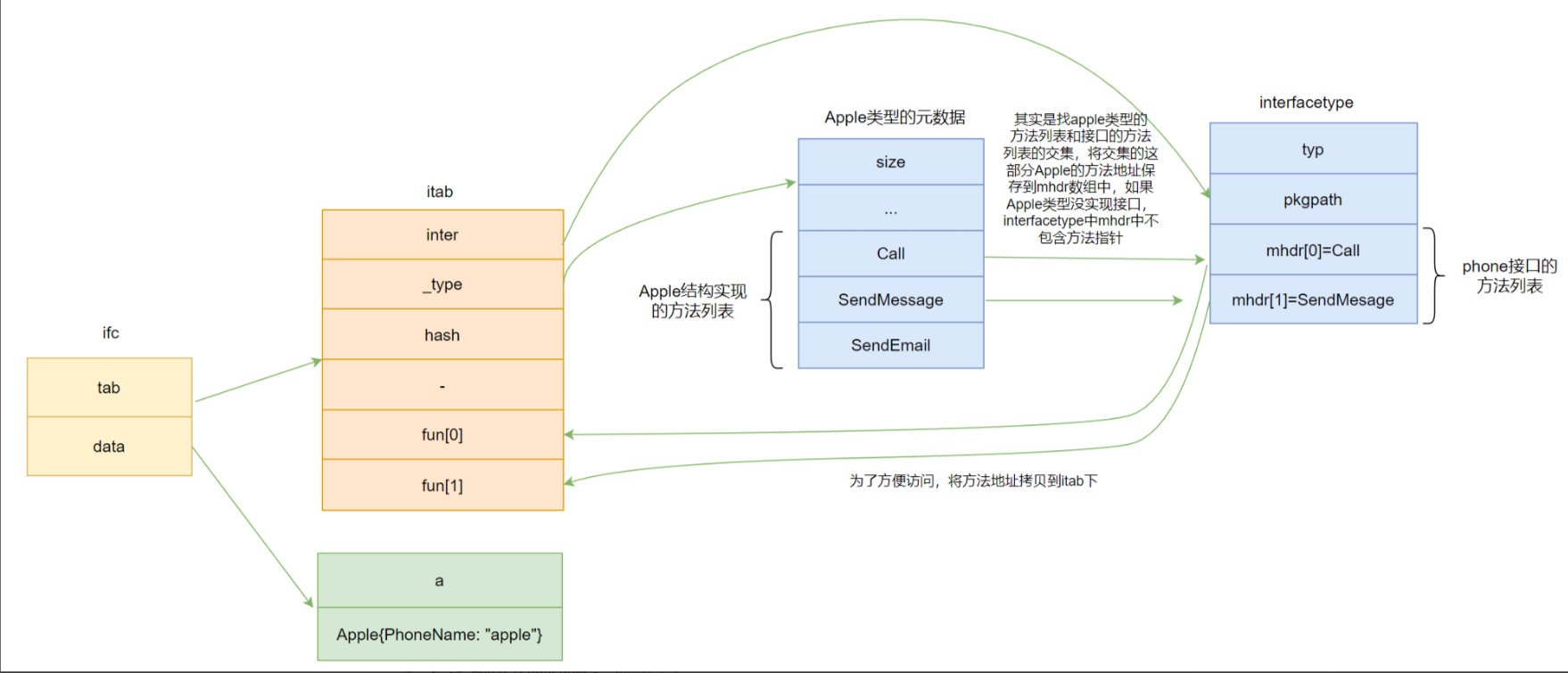
特性:
同一个类型的对象公用一个itab, 缓存记录。计算接口哈希 | (按位或) _type 中的hash 得到最终哈希 可以在全局itable 数组中即可找到 对应的crt 信息表
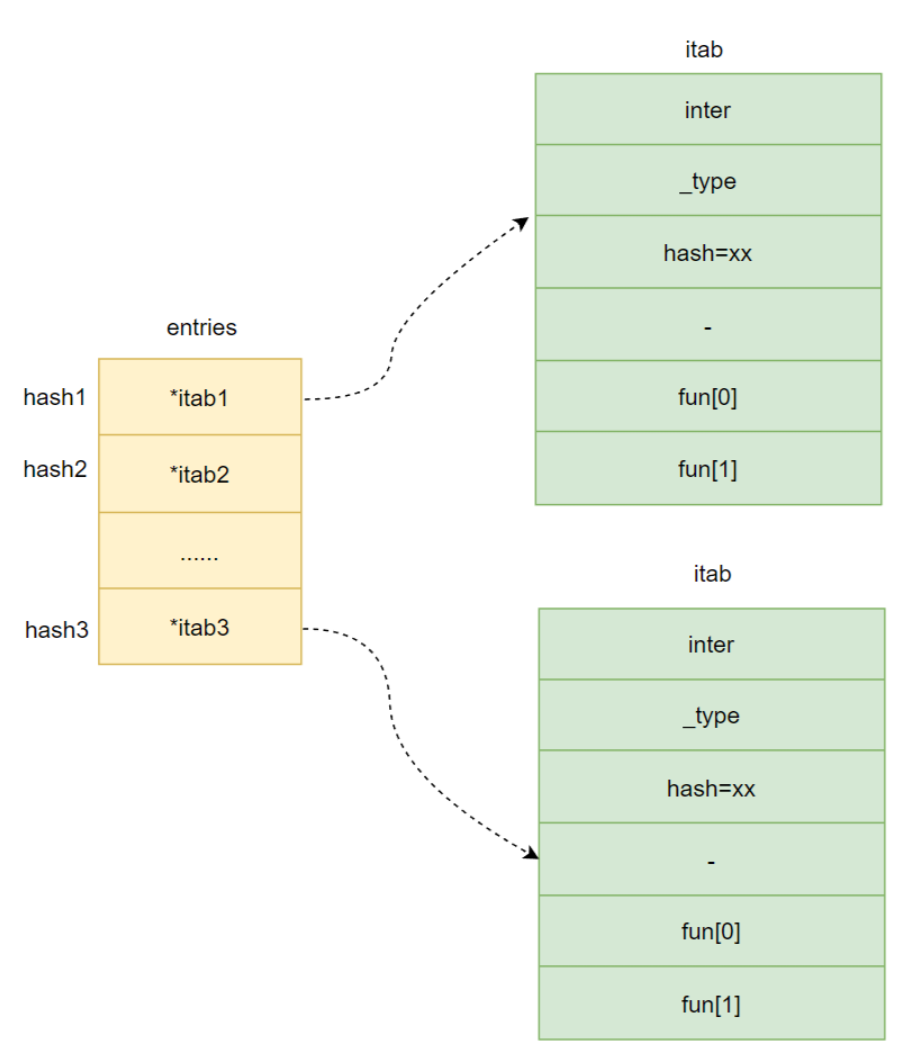
采用开放寻址法解决itable 哈希表 哈希冲突

